hdiutil
Example
创建一个1024MB的ramdisk
1 | # 返回一个ramdisk路径,假设返回的路径是 /dev/disk3 |
创建一个1024MB的ramdisk
1 | # 返回一个ramdisk路径,假设返回的路径是 /dev/disk3 |
MySQL优化原理1:https://www.jianshu.com/p/d7665192aaaf
MySQL优化原理2:https://www.jianshu.com/p/01b9f028d9c7
工作量证明(Proof of Work,简称PoW)为最早的证明方法,也是第一个虚拟币比特币运用的机制。
哈希函数是密码学上计算难度经过反复验证的东西,所以用它来做证明是最有效的,每发出一条信息上传区块链的时候,你要证明你付出了一定的算力,你的证据就是你区块里面的字符串,而加上这个字符串以后,你的区块的哈希值正好小于某个数。
哈希函数的特征告诉我们,你没有任何取巧的方法可以做到这一点,你只能一个个字符串的去尝试。形象来说就是系统为了找出谁有更强大的计算能力,每次会出一道数学题,只有最快解出这道题目的计算机才能进行记账。目前比特币和以太坊均采用此机制。
优点是完全去中心化,节点自有进出,比特币经过了进十年的发展中间经过了黑客攻击、政策限制等不利因素,仍然自我正常运行证明了该工作机制的伟大之处。
缺点POW依赖计算机通过数学运算获取记账权,造成了电力和计算机硬件资源消耗巨大,每次达成共识需要全网所有节点共同参与运算,运行效率低。
权益证明(Proof of Stake,简称PoS)它是PoW的一种升级,主要理念是节点记账权的获得难度与节点持有的权益成反比,根据每个节点所占代币的比例和时间,等比例地降低挖矿难度,从而加快找到随机数的速度。
用户可以购买等价的代币,并把这些代币当作押金放入PoS机制中,这样用户就有机会产生新区块而得到奖励。其在一定程度上减少了数学运算带来的资源消耗,性能也得到了相应的提升,但依然是基于哈希运算。
这个系统中存在一个持币人的集合,他们把手中的代币放入PoS机制中,这样他们就变成验证者。比如对区块链最前面的一个区块而言,PoS算法在验证者中随机选择一个(选择验证者的权重依据他们投入的代币量,比如一个投入押金为1W代币的验证者被选择的概率是一个投入1K代币验证者的10倍),给他权利产生下一个区块。如果在一定时间内,这个验证者没有产生一个区块,则选出第二个验证者代替产生新区块。与PoW一样,PoS以最长的链为准。
优点:在一定程度上缩短了共识达成的时间;不再需要大量消耗能源去挖矿。
缺点:还是需要挖矿,本质上没有解决商业应用的痛点;所有的确认都只是一个概率上的表达,而不是一个确定性的事情,理论上有可能存在其他攻击影响,例如以太坊的DAO攻击事件造成以太坊硬分叉,而ETC随之出现,事实上证明了此次硬分叉的失败。
股份授权证明(DPOS)从英文释义上就能看出是源于POS,它与PoS的主要区别在于节点选举若干代理人,由代理人验证和记账,但其合规监管、性能、资源消耗和容错性与PoS相似。类似于董事会投票,持币者投出一定数量的节点,进行代理验证和记账。
DPoS的工作原理如下:每个股东按其持股比例拥有相应的影响力,51%股东投票的结果将是不可逆且有约束力的,其挑战是通过及时而高效的方法达到“51%批准”。DPoS的投票模式可以每30秒产生一个新区块,并且在正常的网络条件下,区块链分叉的可能性极其小,即使发生也可以在几分钟内得到解决。
DPoS的优点:大幅缩小参与验证和记账节点的数量,可以达到秒级的共识验证。
DPoS的缺点:整个共识机制还是依赖于代币,而很多商业应用是不需要代币的。
瑞波共识机制(Ripple Consensus)算法使一组节点能够基于特殊节点列表形成共识。初始特殊节点列表就像一个俱乐部,要接纳一个新成员,必须由该俱乐部51%的会员投票通过。
共识遵循这些核心成员的“51%权利”,外部人员则没有影响力。由于该俱乐部由中心化开始,它将一直是中心化的,而如果它开始腐化,股东们什么也做不了。与比特币及Peercoin一样,瑞波系统将股东们与其投票权隔开,因此,它比其他系统更中心化。
在使用数据库的时候,心里会假定这里面的数据都是 100% 准确的。回想一下,你在工作中有没有这样做过:
如果你这样做过,或者有过这样的看法,那你一定是在假定:数据都是100%准确的。
现在不妨来思考下,数据库为什么会使你有这样的认知?是因为数据库的开发团队对其测试到位吗?其实,真正起到决定性作用的是数据库背后的设计理念ACID。
ACID: Atomicity, Consistency, Isolation, Durability。
Andreas Reuter 和 TheoHärder 这两位前辈在 1983 年提出它,指出一个数据库“事务”只要满足这4个特性,在任何情况下数据都能保证准确。
“事务”是数据库的执行单元,除了我们平时用显式声明的 transaction 之类关键字包裹的代码外,每一条单独的SQL,也是以事务的形式执行的。比如,当你在一条SQL中同时 insert 多笔数据的时候,一旦发生异常,所有的这几笔数据最终都不会被插入到目标表中,会一并撤销。
在保证达到这个效果的过程中,ACID的四个特性分别起到了什么作用呢?
一句话来概括原子性,用于保证每个事务被视为单个完整的个体,不可分割。满足原子性的事务,要么完全成功,要么完全失败,不允许存在其他中间状态。
通常这点指的是我们同时执行多条SQL语句的时候,可以将这些SQL语句的生效与否捆绑到一起,以保证最终要么全部数据被更新到数据库,要么全部都不更新到数据库。
Example: 小明让小王代购了一些东西回来,需要在微信上支付给他1000元
当小明输入完金额点击“确认转账”之后,执行的 SQL 至少是这样的:
1 | update balance = balance - 1000 from account where id = '小明的 id'`` |
注意,这两条语句中只要任意一条执行失败,而另外一条执行成功,那么从原子性的要求来说,所有执行成功的修改都需要一并撤销,恢复到最初的状态,这个撤销操作我们称为“回滚”。否则,微信体系中的总余额会无故多出或少了 1000 元。
数据库中原子性的主流实现方案是通过日志来做的,每一次操作数据前都会先将当前数据记录到日志中,这样在需要回滚时,我们只要把 Undo Log 中的数据拿出来还原,就可以撤销已经执行成功的操作。
原子性是四个特性中最核心的一个,仅关注当前的这一次操作,不考虑是否存在其它的什么操作。
在上面小明和小王的故事中,如果再出现一个人小张,他也让小王代购了东西要付钱,会出现新的情况,例如
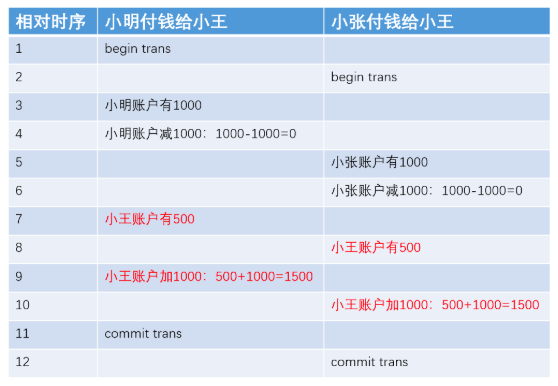
注意一下红字部分。我们发现,这个时候哪怕两次转账的事务分别保证了原子性,并且执行成功,最终的结果还是有可能出错。
上图中的现象,我们称为“丢失更新”(Lost Update)。当然,还有其他可能产生的现象,比如脏读、不可重复读、幻读,等等。
不过,我们暂时不需要过多纠结于这些现象,只要记得:当仅满足原子性的前提下,如果遇到并发执行,依旧会出现数据错误。
所以,这时候我们需要通过隔离性的指导来避免这些问题。隔离性本质上指导解决的是一个资源竞争问题,通俗点说,就是多个事务并发执行后的状态,应该和它们串行执行后的状态是一致的。
在数据库中解决资源竞争问题与其它软件系统无异,就用锁。在数据库中对锁的运用不同,因此产生了不同的隔离级别,不同的隔离级别对应解决的是前面提到的这些异常现象。
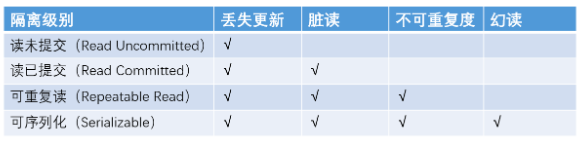
脏读:一个事务中读到(SELECT)了另一个事务还没有提交更新的数据。
不重复读:在同一个事务里,前后两次相同的SELECT语句会读到不同的结果。侧重点在于更新修改数据。
幻读:表示在同一事务中,使用相同的查询语句,第二次查询时,莫名的多出了一些之前不存在数据,或者莫名的不见了一些数据。幻读与不可重复读的区别:幻读的侧重点在于新增和删除。
其实在实际的运用中,遇到的场景会更复杂,所以詹姆士·格雷(Jim Gray)等人在 1995 发表了论文“对 ANSI SQL 隔离级别的批评(A Critique of ANSI SQL Isolation Levels)”将上表做了扩充,增加了游标稳定(Cursor Stability)和快照隔离(Snapshot Isolation)隔离级别,指导我们在做隔离时,可以为获得更好的性能进行一些新的尝试。
当你使用一些云产品写文章的时候,洋洋洒洒写了几千字,安心睡觉去了,第二天起来发现内容停留在刚起笔的那几个字。任何的数据变更完成之后,就相当于成为了“历史”,需要保存下来才能为未来所用。因此数据库需要具备持久性,才能为我们所依赖用于存储数据。
如今,我们几乎都是利用硬盘作为数据库的存储介质,来保证持久性。那么理论上,除非硬盘本身故障,否则都不应该出现这样一种情况:一条SQL变更成功后,发生数据丢失或者数据回到更早的状态。
一致性的含义其实很简单,就是最终结果的对与错,是否是你所希望的结果。任何系统如果无法确保产生的数据结果与预期一致,那么整个系统其实是没有价值的。
回到前面小明和小王的例子。只要小明账户少了1000元,小王账户必须要多出1000元,这才是我们所希望的结果,否则都是错的,也就是“不一致”的。
这么一说,一致性和原子性意思好像差不多啊?关于这点可以这样来理解:
由于一致性只表示一个结果,它只是指引出一个正确的工作方向。而要达到这个正确的结果并不完全是由数据库保证的,它只是一个按规则办事的“监督者”。
但是,它提供了主键、外键、约束、字段类型等,让你可以在不同层面上定义什么是“一致”。一旦不符合你的定义,数据库就会抛出异常来提醒你,这里不符合你的预期了。
原子性(A)、隔离性(I)、持久性(D)是为达到一致性(C)而存在的。
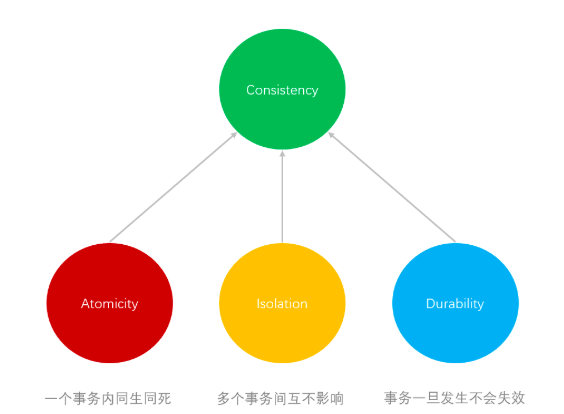
可以理解为,只要满足了原子性(A)、隔离性(I)、持久性(D)那么数据存储层面的一致性(C)自然也就满足了。
不过,站在一个完整的系统角度来说,要达到真正的一致性,还需要我们在Coding的时候有意识的去定义达到“正确结果”的代码逻辑。
聊ACID的原因是为了引出分布式系统中的一个经典定理——CAP。
CAP是指导我们进行多进程之间交互的设计理论,告诉我们该如何去权衡一致性(C)、可用性(A)、分区容错性(P),这也是它这三个字母所表达的含义。
Robert Greiner CAP
第一版:
Any distributed system can’t guaranty C, A, and P simultaneously.
第二版:
In a distributed system (a collection of interconnected nodes that share data), you can only have two out of(从..) the following three guarantees across a write/read pari:
Consistency, Availability, and Partition Tolerance - one of them must be sacrified.
两个版本的差异点:
如果你知道分布式系统理论中的CAP定理,肯定会好奇ACID和CAP两者定义的“一致性”表示的是不是同一个意思。其实不是:
所以你会发现,CAP定理中所表述的“一个请求”类似于数据库ACID中的“一条SQL”,并且还保留了原子性和一致性的含义。然后基于分布式的场景,衍生了分区容错性以及可用性的概念。CAP定理作为后来者,为分布式系统而生,是分布式系统设计的指导方针。理解了 ACID,更有利于你去理解 CAP。
第一版:
All nodes see the same data at the same time.
第二版:
A read is guraranteed to return the most recent write for a given client
两个版本差异点:
第一版:
Every request gets a response on success / failure.
第二版:
A non-failing node will return a reasonable response within a reasonable amount of time(no error or timeout).
两个版本的差异:
第一版:
System continues to work despite message loss or partial failure.
第二版:
The system will continue to funtion when network partitions occur.
两个版本的差异:
CAP理论定义是三个要素中只能取两个,但是在实际的分布式环境中,P是一个必要的要素,因为网络本身无法做到100%可靠,所以分区是一个必然的现象。
假如我们选择CA(放弃P),那么当发生分区现象时,为了保证C,系统需要禁止写入操作,因为当有写入请求时,系统返回error。这又和A冲突了,因为A要去返回no error和no timeout。因此分布式系统理论上不可能选择CA架构,只能选CP或AP架构。
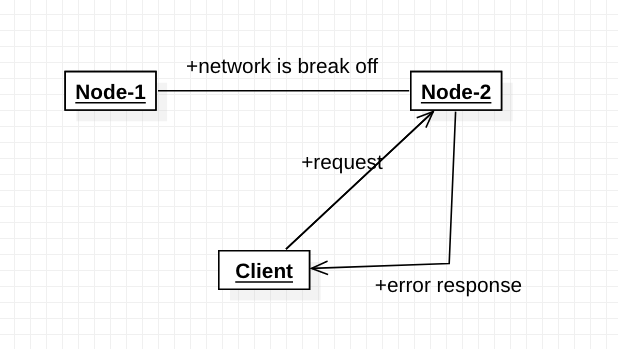
假设,此时所有Node上面的index=0。
为了保证一致性,当分区现象发生后,Node1节点上的index已经更新为1,但由于Node1与Node2之间的网络出了问题,造成数据同步失败,Node2上的index仍然为0。
此时客户端访问Node2,Node2因为C的要求,Node2需要返回Error信息,提示客户端“系统发生了错误”,这种方式违背了A的要求,因此CAP三者只能满足CP。
假设,此时所有Node上面的index=0。
为了保证可用性,当分区现象发生后,Node1节点上的index已经更新为1,但由于Node1与Node2之间的网络出了问题,造成数据同步失败,Node2上的index仍然为0。
此时客户端访问Node2,Node2因为A的要求,Node2将当前index=0的数据返回给客户端,而实际上当前最新的数据是index=1,这就不满足C的要求了,因此CAP三者只能满足AP。
每个系统不可能只处理一种数据,而是包含多种类型的数据,有的数据必须选择CP,有的数据必须选择AP。
如果我们在做设计时,从整个系统的角度去选择CP还是AP,就会发现顾此失彼,无论怎么做都是有问题的。
例如,SSO系统包含用户账号信息(用户ID和密码)、用户其他信息(昵称、性别、手机号等等)。
通常情况下,用户账号数据会选择CP,而用户其他信息会选择AP。如果限定了整个系统为CP,则不符合用户其他信息的应用场景,同理可知,限定系统为AP也是不行的。
例如,账户资金系统,用户可用余额信息选择CA(例如,避免双花问题),用户账户流水信息选择AP或CP。
所以在CAP理论落地实践时,需要将系统内的数据按照不同的应用场景和要求进行分类,每类数据选择不同的策略(AP或CP),而不是直接限定系统所有数据都是同一个策略。
Eric Brewer在定义一致性时,并没有把延迟考虑进去。即当事务提交时,数据能够瞬间复制到所有节点。
但实际情况下,从节点A复制到节点B,总是要花费一定时间的。如果是同机房,耗费时间可能是几毫秒;如果是跨地区的机房,耗费的时间可能是几十毫秒。这就意味着节点A和节点B的数据并不一致。
对于某些严苛的业务场景,例如和金钱相关的用户余额和抢购相关的商品库存,技术上是无法做到分布式场景下完美的一致性。而业务上必须要求一致性,因此单个用户的余额、单个商品的库存,理论上要求选择CP而实际上CP都做不到,只能选择CA。也就是说,只能单点写入,其他节点做备份,无法做到分布式情况下多点写入。
在这种情况下,并不意味着这类系统无法应用分布式架构,只是说“单个用户余额、单个商品库存”无法做到分布式,但系统整体还是可以应用分布式架构的。
例如,将用户分区的分布式架构图
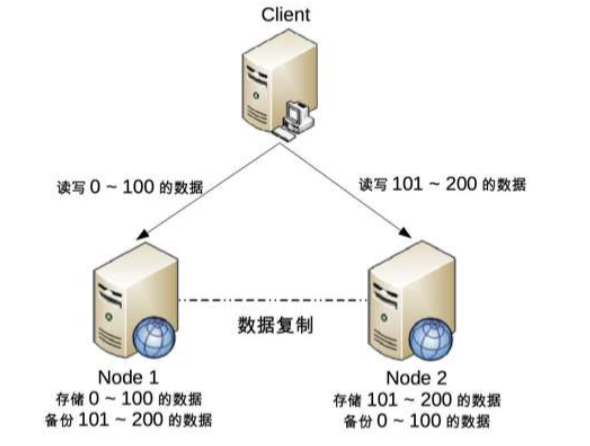
把用户分散在不同的Node上,即使某个Node出现了故障,也仅仅是部分用户不能操作,但是大部分用户还是可以进行正常操作的。
CAP理论告诉我们,分布式系统只能选择CP或AP,前提条件是“系统发生了分区现象”。如果没有发生分区现象,即P不存在的时候(节点间的网络一切正常),此时没有必要放弃C或A,CA都可以保证。
这就要求架构设计的时候既要考虑分区发生时选择CP还是CA,也要考虑分区没有发生时如何保证CA。
例如,SSO系统中,用户账户数据可以通过消息队列实现CA;用户信息可以采用“数据库同步”的方式实现CA。
CAP理论的“牺牲”只是说在分区过程中我们无法保证C或A,但并不意味着我们什么都不做。因为在系统整个运行周期中,大部分时间都是正常的,发生分区现象的时间并不长。
例如,99.99%可用性的系统,一年运行下来,不可用的时间只有50分钟、99.999%可用性的系统,不可用的时间只有5分钟。
分区期间放弃C或A,并不意味着永远放弃C和A,我们在分区期间进行一些操作,从而让分区故障解决后,系统能够重新达到CA的状态。
比较常见的解决方案是,在分区期间记录一些日志,当分区故障解决后,系统根据日志进行数据恢复,使得重新达到CA状态。
BASE: Basically Available, Soft State, Eventually Consistency
分布式系统在出现故障时,允许损失部分可用性,即保证核心可用。
例如,SSO系统,核心是登录功能,部分是注册功能。
允许系统存在中间状态,而中间状态不会影响系统整体可用性。这里的中间状态就是CAP理论中的数据不一致性。
系统中所有数据副本经过一定时间后,最终能够达到一致的状态。
这里的“最终”和“一定时间”,与数据的特性是强关联的,不同的数据能够容忍的不一致时间是不同的。
例如,用户账号数据最好能在一分钟就达到一致状态,因为用户在节点A注册或登录后,1分钟内不太可能立刻切换到另一个节点,但10分钟后可能就重新登录到另一个节点。
用户发布的最新微博,可以容忍30分钟内达到一致状态。因为对于用户来说,看不到某个明星发布的最新微博,用户是无感知的,会认为明星没有发布微博。
“最终”的含义就是不管多长时间,最终还是要达到一致性的状态。
BASE理论本质上是对CAP的延伸和补充,更具体地说,是对CAP中AP方案的一个补充。
CAP理论是忽略延时的,而实际应用中延时是无法避免的。
这一点就意味着完美的CP场景是不存在的,即使是几毫秒的数据复制延迟,在这几毫秒时间间隔内,系统是不符合CP要求的。因此CAP中的CP方案,实际上也是实现了最终一致性,只是“一定时间”是指几毫秒。
AP方案中牺牲一致性只是指分区期间,而不是永远放弃一致性。
这一点其实就是BASE理论延伸的地方,分期区间牺牲一致性,但分区故障恢复后,系统应该达到最终一致性。
对于ACID,CAP和BASE对比分析总结:
https://www.infoq.cn/article/Q1Dlq-tcyjEX6GVmRuoy
http://www.zsythink.net/archives/1233
Robert Greiner CAP 1.0: http://robertgreiner.com/2014/06/cap-theorem-explained/
Robert Greiner CAP 2.0: http://robertgreiner.com/2014/08/cap-theorem-revisited/
Zookeeper的Leader选举: http://www.cnblogs.com/leesf456/p/6107600.html
Scopes play an important part in ownership, borrowing, and lifetimes.
That is, they indicate to the compiler when borrows are valid, when resources can be freed, and when variables are created or destroyed.
Rust enforces RAII, so whenever an object goes out of scope, its destructor is called and its owned resources are freed.
RAII: Resource Acquisition Is Initialization
This behavior shields against resource leak bugs, so you’ll never have to manually free memory or worry about memory leaks again!
Here’s a quick showcase:
1 | fn create_box() { |
memory analyzer:rustc main.rs && valgrind ./main
The notion of a destructor in Rust is provided through the Drop trait. The destructor is called when the resource goes out of scope.
This trait is not required to be implemented for every type, only implement it for your type if you require its own destructor logic.
showcase:
1 | struct ToDrop; |
1 | Made a ToDrop! |
Because variables are in charge of freeing their own resources, resources can only have one owner.
This also prevents resources from being freed more than once. Note that not all variables own resources (e.g. references).
When doing assignments (let x = y) or passing function arguments by value (foo(x)), the ownership of the resources is transferred. In Rust-speak, this is known as a move.
After moving resources, the previous owner can no longer be used. This avoids creating dangling pointers.
Example:
1 | // This function takes ownership of the heap allocated memory |
可以看到,不论是b,还是a,在调用destroy_box()后,都失去了ownership。
Most of the time, we’d like to access data without taking ownership over it. To accomplish this, Rust uses a borrowing mechanism. Instead of passing objects by value (T), objects can be passed by reference (&T).
Example:
1 | // This function takes ownership of a box and destroys it |
在block里面,调用eat_box_i32()尝试destroy boxed_i32前,boxed_i32已经被_ref_to_i32借用了,而且eat_box_i32()被包含在_ref_to_i32的scope里面,此时,eat_box_i32()试图destroy boxed_i32是不可能的事情。
Mutable data can be mutably borrowed using &mut T. This is called a mutable reference and gives read/write access to the borrower.
In contrast, &T borrows the data via an immutable reference, and the borrower can read the data but not modify it:
Example:
1 |
|
When data is immutably borrowed, it also freezes. Frozen data can’t be modified via the original object until all references to it go out of scope:
1 | fn main() { |
Data can be immutably borrowed any number of times, but while immutably borrowed, the original data can’t be mutably borrowed. On the other hand, only one mutable borrow is allowed at a time. The original data can be borrowed again only after the mutable reference goes out of scope.
1 | struct Point { x: i32, y: i32, z: i32 } |
在第一个block里面,point已经被borrowed_point借用,此时如果试图进行mutable borrow是禁止的,但是immutable是可以多次的。即,如果一个对象已经被borrow了,都不能再进行mutable borrrow,除非borrow已经结束。
在第二个block里面,point已经被mutable borrow,此时即使是immutable borrow也是不允许的。
When doing pattern matching or destructuring via the let binding, the ref keyword can be used to take references to the fields of a struct/tuple.
The example below shows a few instances where this can be useful:
1 |
|
1 | ref_c1 equals ref_c2: true |
A lifetime is a construct the compiler (or more specifically, its borrow checker) uses to ensure all borrows are valid.
Specifically, a variable’s lifetime begins when it is created and ends when it is destroyed. While lifetimes and scopes are often referred to together, they are not the same.
Take, for example, the case where we borrow a variable via &. The borrow has a lifetime that is determined by where it is declared.
As a result, the borrow is valid as long as it ends before the lender is destroyed. However, the scope of the borrow is determined by where the reference is used.
showcase:
1 | // Lifetimes are annotated below with lines denoting the creation |
Note that no names or types are assigned to label lifetimes. This restricts how lifetimes will be able to be used as we will see.
需要注意的是,lifetime需要开发人员自己去标记出来,IDE并不会帮助你标记一个变量的lifetime。
从上面的代码可知,i的lifetime和scope的周期完全不同,scope周期 <= lifetime周期。
Some lifetime patterns are overwhelmingly(强制地) common and so the borrow checker will implicitly add them to save typing and to improve readability. This process of implicit addition is called elision. Elision exists in Rust solely because these patterns are common.
The following code shows a few examples of elision. For a more comprehensive description of elision
1 | // `elided_input` and `annotated_input` essentially have identical signatures |
Ignoring elision, function signatures with lifetimes have a few constraints:
Additionally, note that returning references without input is banned if it would result in returning references to invalid data. The following example shows off(强调) some valid forms of functions with lifetimes:
1 | // One input reference with lifetime `'a` which must live |
如果function有返回值,则返回值必须声明lifetime。
1 | // `print_refs` takes two references to `i32` which have different |
1 | fn main() { |
1 | function: 2 |
1 | fn main() { |
1 | `color`: green |
1 | fn is_odd(n: u32) -> bool { |