Introduction
在使用数据库的时候,心里会假定这里面的数据都是 100% 准确的。回想一下,你在工作中有没有这样做过:
- 有人给你反映了一个问题,说数据错了,你的自然反应是去检查代码有没有问题,而不会想到去确认数据库有没有问题?
- 为了更快更方便地执行单元测试,你认为通过 Mock 数据加上断言(assertion)来代替数据库中实际存储的数据是完全没问题的。
如果你这样做过,或者有过这样的看法,那你一定是在假定:数据都是100%准确的。
现在不妨来思考下,数据库为什么会使你有这样的认知?是因为数据库的开发团队对其测试到位吗?其实,真正起到决定性作用的是数据库背后的设计理念ACID。
What’s ACID
ACID: Atomicity, Consistency, Isolation, Durability。
Andreas Reuter 和 TheoHärder 这两位前辈在 1983 年提出它,指出一个数据库“事务”只要满足这4个特性,在任何情况下数据都能保证准确。
“事务”是数据库的执行单元,除了我们平时用显式声明的 transaction 之类关键字包裹的代码外,每一条单独的SQL,也是以事务的形式执行的。比如,当你在一条SQL中同时 insert 多笔数据的时候,一旦发生异常,所有的这几笔数据最终都不会被插入到目标表中,会一并撤销。
在保证达到这个效果的过程中,ACID的四个特性分别起到了什么作用呢?
Atomicity
一句话来概括原子性,用于保证每个事务被视为单个完整的个体,不可分割。满足原子性的事务,要么完全成功,要么完全失败,不允许存在其他中间状态。
通常这点指的是我们同时执行多条SQL语句的时候,可以将这些SQL语句的生效与否捆绑到一起,以保证最终要么全部数据被更新到数据库,要么全部都不更新到数据库。
Example: 小明让小王代购了一些东西回来,需要在微信上支付给他1000元
当小明输入完金额点击“确认转账”之后,执行的 SQL 至少是这样的:
1 | update balance = balance - 1000 from account where id = '小明的 id'`` |
注意,这两条语句中只要任意一条执行失败,而另外一条执行成功,那么从原子性的要求来说,所有执行成功的修改都需要一并撤销,恢复到最初的状态,这个撤销操作我们称为“回滚”。否则,微信体系中的总余额会无故多出或少了 1000 元。
数据库中原子性的主流实现方案是通过日志来做的,每一次操作数据前都会先将当前数据记录到日志中,这样在需要回滚时,我们只要把 Undo Log 中的数据拿出来还原,就可以撤销已经执行成功的操作。
原子性是四个特性中最核心的一个,仅关注当前的这一次操作,不考虑是否存在其它的什么操作。
Isolation
在上面小明和小王的故事中,如果再出现一个人小张,他也让小王代购了东西要付钱,会出现新的情况,例如
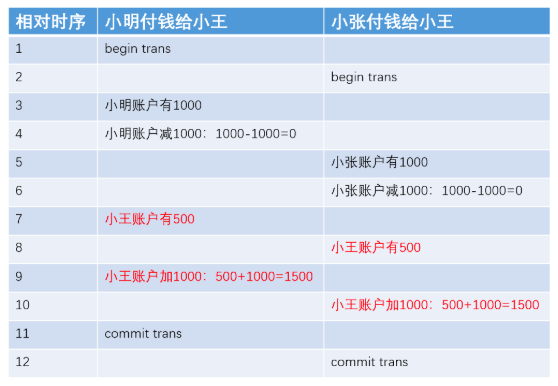
注意一下红字部分。我们发现,这个时候哪怕两次转账的事务分别保证了原子性,并且执行成功,最终的结果还是有可能出错。
上图中的现象,我们称为“丢失更新”(Lost Update)。当然,还有其他可能产生的现象,比如脏读、不可重复读、幻读,等等。
不过,我们暂时不需要过多纠结于这些现象,只要记得:当仅满足原子性的前提下,如果遇到并发执行,依旧会出现数据错误。
所以,这时候我们需要通过隔离性的指导来避免这些问题。隔离性本质上指导解决的是一个资源竞争问题,通俗点说,就是多个事务并发执行后的状态,应该和它们串行执行后的状态是一致的。
在数据库中解决资源竞争问题与其它软件系统无异,就用锁。在数据库中对锁的运用不同,因此产生了不同的隔离级别,不同的隔离级别对应解决的是前面提到的这些异常现象。
- 读未提交(Read Uncommitted)解决了丢失更新
- 读已提交(Read committed)解决了脏读
- 可重复读(Repeatable Read)解决了不可重复读问题
- 最高级别的可序列化(Serializable)解决了全部这 4 个问题,即丢失更新、脏读、不可重复度、幻读。
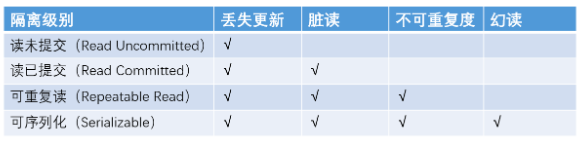
脏读:一个事务中读到(SELECT)了另一个事务还没有提交更新的数据。
不重复读:在同一个事务里,前后两次相同的SELECT语句会读到不同的结果。侧重点在于更新修改数据。
幻读:表示在同一事务中,使用相同的查询语句,第二次查询时,莫名的多出了一些之前不存在数据,或者莫名的不见了一些数据。幻读与不可重复读的区别:幻读的侧重点在于新增和删除。
其实在实际的运用中,遇到的场景会更复杂,所以詹姆士·格雷(Jim Gray)等人在 1995 发表了论文“对 ANSI SQL 隔离级别的批评(A Critique of ANSI SQL Isolation Levels)”将上表做了扩充,增加了游标稳定(Cursor Stability)和快照隔离(Snapshot Isolation)隔离级别,指导我们在做隔离时,可以为获得更好的性能进行一些新的尝试。
Durability
当你使用一些云产品写文章的时候,洋洋洒洒写了几千字,安心睡觉去了,第二天起来发现内容停留在刚起笔的那几个字。任何的数据变更完成之后,就相当于成为了“历史”,需要保存下来才能为未来所用。因此数据库需要具备持久性,才能为我们所依赖用于存储数据。
如今,我们几乎都是利用硬盘作为数据库的存储介质,来保证持久性。那么理论上,除非硬盘本身故障,否则都不应该出现这样一种情况:一条SQL变更成功后,发生数据丢失或者数据回到更早的状态。
Consistency
一致性的含义其实很简单,就是最终结果的对与错,是否是你所希望的结果。任何系统如果无法确保产生的数据结果与预期一致,那么整个系统其实是没有价值的。
回到前面小明和小王的例子。只要小明账户少了1000元,小王账户必须要多出1000元,这才是我们所希望的结果,否则都是错的,也就是“不一致”的。
这么一说,一致性和原子性意思好像差不多啊?关于这点可以这样来理解:
- 原子性关注的是关系和过程,确保指定的SQL之间是一个命运共同体。比如鸡蛋孵小鸡这个过程,必然是鸡蛋破了后小鸡再出来,而不是鸡蛋破了,小鸡不见了或者鸡蛋没破,不知道从哪哪冒出来个小鸡。
- 而一致性关注的是结果,这个结果的预期是你来定的,如何达到这个结果的过程并不是它所包含的概念。还是鸡蛋孵小鸡这个事,比如你预期一个鸡蛋里只能孵出一个小鸡,那么如果最终9个鸡蛋里出现了10个小鸡,这时就是不一致的。
由于一致性只表示一个结果,它只是指引出一个正确的工作方向。而要达到这个正确的结果并不完全是由数据库保证的,它只是一个按规则办事的“监督者”。
但是,它提供了主键、外键、约束、字段类型等,让你可以在不同层面上定义什么是“一致”。一旦不符合你的定义,数据库就会抛出异常来提醒你,这里不符合你的预期了。
ACID 间的联系
原子性(A)、隔离性(I)、持久性(D)是为达到一致性(C)而存在的。
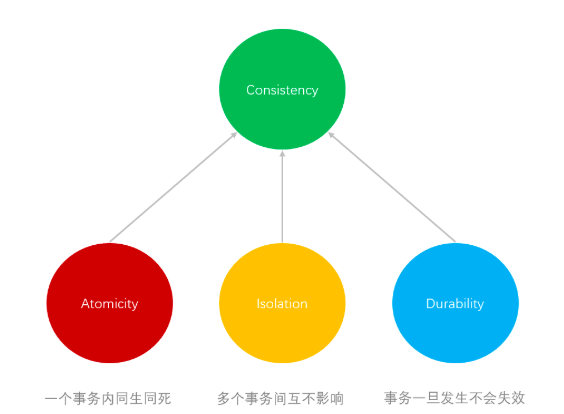
可以理解为,只要满足了原子性(A)、隔离性(I)、持久性(D)那么数据存储层面的一致性(C)自然也就满足了。
不过,站在一个完整的系统角度来说,要达到真正的一致性,还需要我们在Coding的时候有意识的去定义达到“正确结果”的代码逻辑。
What’s CAP
聊ACID的原因是为了引出分布式系统中的一个经典定理——CAP。
CAP是指导我们进行多进程之间交互的设计理论,告诉我们该如何去权衡一致性(C)、可用性(A)、分区容错性(P),这也是它这三个字母所表达的含义。
Robert Greiner CAP
第一版:
Any distributed system can’t guaranty C, A, and P simultaneously.
第二版:
In a distributed system (a collection of interconnected nodes that share data), you can only have two out of(从..) the following three guarantees across a write/read pari:
Consistency, Availability, and Partition Tolerance - one of them must be sacrified.
两个版本的差异点:
- 第二版定义了什么才是CAP理论探讨的分布式系统(强调interconnected and share data)。为什么要强调这两点?因为分布式系统并不一定会互联和共享数据。比如Memcache,相互之间就没有连接和共享数据,因此Memcache集群并不符合CAP理论探讨的对象。而MySQL集群就是互联和进行数据复制的,因此是CAP理论探讨的对象。
- 第二版强调了 write/read pair,CAP关注的是对数据的读写操作,而不是分布式系统的所有功能。例如,ZooKeeper的选举机制就不是CAP探讨的对象。
如果你知道分布式系统理论中的CAP定理,肯定会好奇ACID和CAP两者定义的“一致性”表示的是不是同一个意思。其实不是:
- 描述的主体不同,ACID中的C指的是数据库事务的一致性,而CAP中的C指的是程序之间请求的一致性。
- 对结果的定义也有些差异,CAP中的C除了一致性之外还带着一些原子性的意思,一次操作中产生的多个请求要被视为一个完整的个体,不可分割,这个特点和数据库中的原子性是一致的。
所以你会发现,CAP定理中所表述的“一个请求”类似于数据库ACID中的“一条SQL”,并且还保留了原子性和一致性的含义。然后基于分布式的场景,衍生了分区容错性以及可用性的概念。CAP定理作为后来者,为分布式系统而生,是分布式系统设计的指导方针。理解了 ACID,更有利于你去理解 CAP。
Consistency
第一版:
All nodes see the same data at the same time.
第二版:
A read is guraranteed to return the most recent write for a given client
两个版本差异点:
- 第一版从Node角度描述,第二版从Client的角度描述。第二版更符合我们观察和评估系统的方式,即站在客户端的角度来观察系统的特征和行为。
- 第一版关键词see,第二版read。第二版从Client的读写角度来描述一致性,定义更加精确。
- 第一版强调同一时刻所有Node拥有相同的数据,第二版强调Client读取到总是最新的数据(这对于集群中的多个节点来说,可能在同一时刻拥有不同的数据。对于系统执行事务来说,在事务过程中,系统其实处于一个不一致的状态,不同节点的数据并不完全一致,此时Client是无法读取到没有提交的数据。但是当事务提交以后,Client是可以读取到事务写入的数据,如果事务失败则会进行回滚,Client也不会读取到事务中间写入的数据)。
Available
第一版:
Every request gets a response on success / failure.
第二版:
A non-failing node will return a reasonable response within a reasonable amount of time(no error or timeout).
两个版本的差异:
- 第一版强调 every request,第二版强调 a non-failing node。第一版并不严谨,因为只有非故障节点才能满足可用性要求,如果节点本身就故障了,发给节点的请求不一定就能得到一个响应。
- 第一版的 success / failure 太宽泛,在实际中没有指导意义,第二版明确了不能超时和不能出错,但要提出合理的结果,需要注意的是没有说”正确”的结果,例如,应该返回200但实际是301,肯定是不正确的结果,但是一个合理的结果。
Partition Tolerance
第一版:
System continues to work despite message loss or partial failure.
第二版:
The system will continue to funtion when network partitions occur.
两个版本的差异:
- 第一版用workd,第二版用function。work强调运行,只要系统不宕机,都可以说系统在work,即使返回错误,或拒绝服务都是在work。function强调履行其职能(正确地发挥其功能作用),即返回reasonable response。
- 第一版描述分区用的是message loss or partial failure,第二版直接用network partitions。第一版只是说明了message loss造成了分区,但没有详细解释message loss指的是什么,如果说的是丢包,那就太狭隘了,因为它只是网路故障中的一种。而第二版直接说现象,即发生了分区现象。造成这个现象的原因可能是丢包,连接中断或拥塞等等,只要导致了网络分区,就通通算在一起。
CAP应用
CAP理论定义是三个要素中只能取两个,但是在实际的分布式环境中,P是一个必要的要素,因为网络本身无法做到100%可靠,所以分区是一个必然的现象。
假如我们选择CA(放弃P),那么当发生分区现象时,为了保证C,系统需要禁止写入操作,因为当有写入请求时,系统返回error。这又和A冲突了,因为A要去返回no error和no timeout。因此分布式系统理论上不可能选择CA架构,只能选CP或AP架构。
CP架构
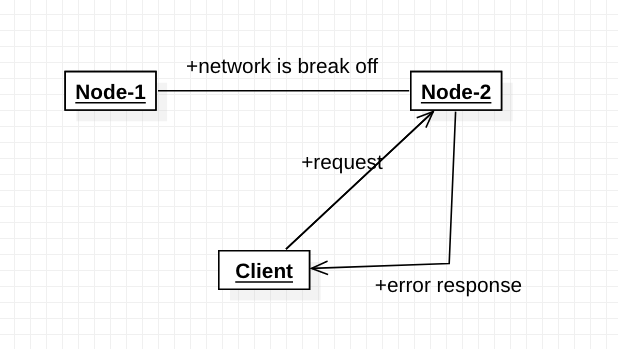
假设,此时所有Node上面的index=0。
为了保证一致性,当分区现象发生后,Node1节点上的index已经更新为1,但由于Node1与Node2之间的网络出了问题,造成数据同步失败,Node2上的index仍然为0。
此时客户端访问Node2,Node2因为C的要求,Node2需要返回Error信息,提示客户端“系统发生了错误”,这种方式违背了A的要求,因此CAP三者只能满足CP。
AP架构
假设,此时所有Node上面的index=0。
为了保证可用性,当分区现象发生后,Node1节点上的index已经更新为1,但由于Node1与Node2之间的网络出了问题,造成数据同步失败,Node2上的index仍然为0。
此时客户端访问Node2,Node2因为A的要求,Node2将当前index=0的数据返回给客户端,而实际上当前最新的数据是index=1,这就不满足C的要求了,因此CAP三者只能满足AP。
CPA关注的粒度是数据,而不是整个系统
每个系统不可能只处理一种数据,而是包含多种类型的数据,有的数据必须选择CP,有的数据必须选择AP。
如果我们在做设计时,从整个系统的角度去选择CP还是AP,就会发现顾此失彼,无论怎么做都是有问题的。
例如,SSO系统包含用户账号信息(用户ID和密码)、用户其他信息(昵称、性别、手机号等等)。
通常情况下,用户账号数据会选择CP,而用户其他信息会选择AP。如果限定了整个系统为CP,则不符合用户其他信息的应用场景,同理可知,限定系统为AP也是不行的。
例如,账户资金系统,用户可用余额信息选择CA(例如,避免双花问题),用户账户流水信息选择AP或CP。
所以在CAP理论落地实践时,需要将系统内的数据按照不同的应用场景和要求进行分类,每类数据选择不同的策略(AP或CP),而不是直接限定系统所有数据都是同一个策略。
CAP是忽略网络延迟的
Eric Brewer在定义一致性时,并没有把延迟考虑进去。即当事务提交时,数据能够瞬间复制到所有节点。
但实际情况下,从节点A复制到节点B,总是要花费一定时间的。如果是同机房,耗费时间可能是几毫秒;如果是跨地区的机房,耗费的时间可能是几十毫秒。这就意味着节点A和节点B的数据并不一致。
对于某些严苛的业务场景,例如和金钱相关的用户余额和抢购相关的商品库存,技术上是无法做到分布式场景下完美的一致性。而业务上必须要求一致性,因此单个用户的余额、单个商品的库存,理论上要求选择CP而实际上CP都做不到,只能选择CA。也就是说,只能单点写入,其他节点做备份,无法做到分布式情况下多点写入。
在这种情况下,并不意味着这类系统无法应用分布式架构,只是说“单个用户余额、单个商品库存”无法做到分布式,但系统整体还是可以应用分布式架构的。
例如,将用户分区的分布式架构图
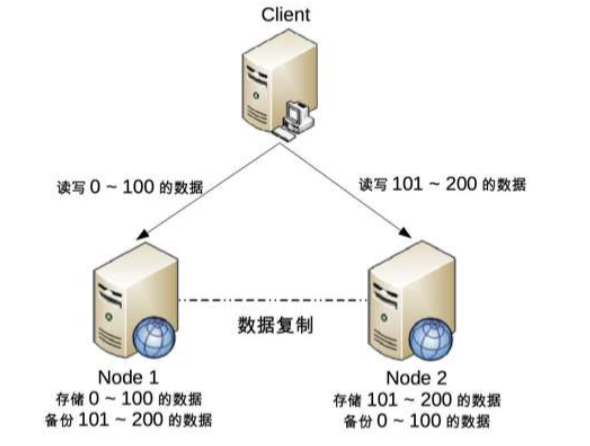
把用户分散在不同的Node上,即使某个Node出现了故障,也仅仅是部分用户不能操作,但是大部分用户还是可以进行正常操作的。
正常运行情况下,不存在CP和AP的选择,可以同时满足CA
CAP理论告诉我们,分布式系统只能选择CP或AP,前提条件是“系统发生了分区现象”。如果没有发生分区现象,即P不存在的时候(节点间的网络一切正常),此时没有必要放弃C或A,CA都可以保证。
这就要求架构设计的时候既要考虑分区发生时选择CP还是CA,也要考虑分区没有发生时如何保证CA。
例如,SSO系统中,用户账户数据可以通过消息队列实现CA;用户信息可以采用“数据库同步”的方式实现CA。
放弃不等于什么都不做,需要为分区恢复做准备
CAP理论的“牺牲”只是说在分区过程中我们无法保证C或A,但并不意味着我们什么都不做。因为在系统整个运行周期中,大部分时间都是正常的,发生分区现象的时间并不长。
例如,99.99%可用性的系统,一年运行下来,不可用的时间只有50分钟、99.999%可用性的系统,不可用的时间只有5分钟。
分区期间放弃C或A,并不意味着永远放弃C和A,我们在分区期间进行一些操作,从而让分区故障解决后,系统能够重新达到CA的状态。
比较常见的解决方案是,在分区期间记录一些日志,当分区故障解决后,系统根据日志进行数据恢复,使得重新达到CA状态。
BASE
BASE: Basically Available, Soft State, Eventually Consistency
Basically Available
分布式系统在出现故障时,允许损失部分可用性,即保证核心可用。
例如,SSO系统,核心是登录功能,部分是注册功能。
Soft State
允许系统存在中间状态,而中间状态不会影响系统整体可用性。这里的中间状态就是CAP理论中的数据不一致性。
Eventually Consistency
系统中所有数据副本经过一定时间后,最终能够达到一致的状态。
这里的“最终”和“一定时间”,与数据的特性是强关联的,不同的数据能够容忍的不一致时间是不同的。
例如,用户账号数据最好能在一分钟就达到一致状态,因为用户在节点A注册或登录后,1分钟内不太可能立刻切换到另一个节点,但10分钟后可能就重新登录到另一个节点。
用户发布的最新微博,可以容忍30分钟内达到一致状态。因为对于用户来说,看不到某个明星发布的最新微博,用户是无感知的,会认为明星没有发布微博。
“最终”的含义就是不管多长时间,最终还是要达到一致性的状态。
小结
BASE理论本质上是对CAP的延伸和补充,更具体地说,是对CAP中AP方案的一个补充。
CAP理论是忽略延时的,而实际应用中延时是无法避免的。
这一点就意味着完美的CP场景是不存在的,即使是几毫秒的数据复制延迟,在这几毫秒时间间隔内,系统是不符合CP要求的。因此CAP中的CP方案,实际上也是实现了最终一致性,只是“一定时间”是指几毫秒。
AP方案中牺牲一致性只是指分区期间,而不是永远放弃一致性。
这一点其实就是BASE理论延伸的地方,分期区间牺牲一致性,但分区故障恢复后,系统应该达到最终一致性。
对于ACID,CAP和BASE对比分析总结:
- ACID是数据库事务完整性的理论
- CAP是分布式系统的设计理论
- BASE是CAP理论中AP方案的延伸
Refer
https://www.infoq.cn/article/Q1Dlq-tcyjEX6GVmRuoy
http://www.zsythink.net/archives/1233
Robert Greiner CAP 1.0: http://robertgreiner.com/2014/06/cap-theorem-explained/
Robert Greiner CAP 2.0: http://robertgreiner.com/2014/08/cap-theorem-revisited/
Zookeeper的Leader选举: http://www.cnblogs.com/leesf456/p/6107600.html