MySQL Upgrade
SQL
safe-updates
在应用 BUG或者 DBA误操作的情况下,会发生对全表进行更新:update delete 的情况。MySQL提供 sql_safe_updates 来限制次操作。】
1 | set sql_safe_updates = 1; |
设置之后,会限制update delete 中不带 where 条件的SQL 执行,较严格。会对已有线上环境带来不利影响。对新系统、应用做严格审核,可以确保不会发生全表更新的问题。
由此,update 时,在没有 where 条件或者where 后不是索引字段时,必须使用 limit;在有 where 条件时,为索引字段
相关报错
Error Code: 1175. You are using safe update mode and you tried to update a table without a WHERE that uses a KEY column To disable safe mode, toggle the option in Preferences -> SQL Queries and reconnect.
因为MySql运行在safe-updates模式下,该模式会导致非主键条件下无法执行update或者delete命令,执行命令
修改下数据库模式,SET SQL_SAFE_UPDATES = 0,安全起见,执行完操作后,建议在恢复成默认状态1
1 | SET SQL_SAFE_UPDATES = 0; |
Java Queue
ConcurrentLinkedQueue
peek操作是获取链表头部一个元素(只读取不移除)
poll操作是在链表头部获取并且移除一个元素
它实现了BlockingQueue接口,BlockingQueue接口继承自java.util.Queue接口,并在这个接口的基础上增加了take和put方法,这两个方法正是队列操作的阻塞版本。
ConcurrentLinkedQueue的API原来.size()是要遍历一遍集合的,难怪那么慢,所以尽量要避免用size而改用isEmpty()
LinkedBlockingQueue
默认最大是Integer.MAX_VALUE,其中主要用到put和take方法,put方法在队列满的时候会阻塞直到有队列成员被消费,take方法在队列空的时候会阻塞,直到有队列成员被放进来。
CopyOnWriteArrayList
Java Map
HashMap
Class主要成员
transient int size:记录了Map中KV对的个数
loadFactor:装载印子,用来衡量HashMap满的程度。loadFactor的默认值为0.75f。(static final float DEFAULT_LOAD_FACTOR = 0.75f)
int threshold:临界值,当实际KV个数超过threshold时,HashMap会将容量扩容,threshold=容量*加载因子
capacity:容量,如果不指定,默认容量是16。(static final int DEFAULT_INITIAL_CAPACITY = 1 << 4)
- size和capacity的关系
HashMap就像一个“桶”,那么capacity就是这个桶“当前”最多可以装多少元素,而size表示这个桶已经装了多少元素。
- 动态扩容
如果你需要存储大量数据,你应该在创建HashMap时指定一个初始的容量,这个容量应该接近你期望的大小。
默认情况下HashMap的容量是16,但是,如果用户通过构造函数指定了一个数字作为容量,那么Hash会选择大于该数字的第一个2的幂作为容量。(1->1、7->8、9->16)
HashMap的扩容条件就是当HashMap中的元素个数(size)超过临界值(threshold)时就会自动扩容。
在HashMap中,threshold = loadFactor * capacity。
loadFactor是装载因子,表示HashMap满的程度,默认值为0.75f,设置成0.75有一个好处,那就是0.75正好是3/4,而capacity又是2的幂。所以,两个数的乘积都是整数。
对于一个默认的HashMap来说,默认情况下,当其size大于12(16*0.75)时就会触发扩容,每次扩充为原来的2倍。
如果数据量不大,重建内部数组的操作会很快,但是数据量很大时,花费的时间可能会从秒级到分钟级。通过初始化时指定Map期望的大小,你可以避免调整大小操作带来的消耗。
但这里也有一个缺点:如果你将数组设置的非常大,例如2^28,但你只是用了数组中的2^26个桶,那么你将会浪费大量的内存(在这个示例中大约是2^30字节)。
- 常见的Hash函数
直接定址法:直接以关键字k或者k加上某个常数(k+c)作为哈希地址。
数字分析法:提取关键字中取值比较均匀的数字作为哈希地址。
除留余数法:用关键字k除以某个不大于哈希表长度m的数p,将所得余数作为哈希表地址。
分段叠加法:按照哈希表地址位数将关键字分成位数相等的几部分,其中最后一部分可以比较短。然后将这几部分相加,舍弃最高进位后的结果就是该关键字的哈希地址。
平方取中法:如果关键字各个部分分布都不均匀的话,可以先求出它的平方值,然后按照需求取中间的几位作为哈希地址。
伪随机数法:采用一个伪随机数当作哈希函数。
衡量一个哈希函数的好坏的重要指标就是发生碰撞的概率以及发生碰撞的解决方案。任何哈希函数基本都无法彻底避免碰撞,常见的解决碰撞的方法有以下几种:
开放定址法:开放定址法就是一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录存入。
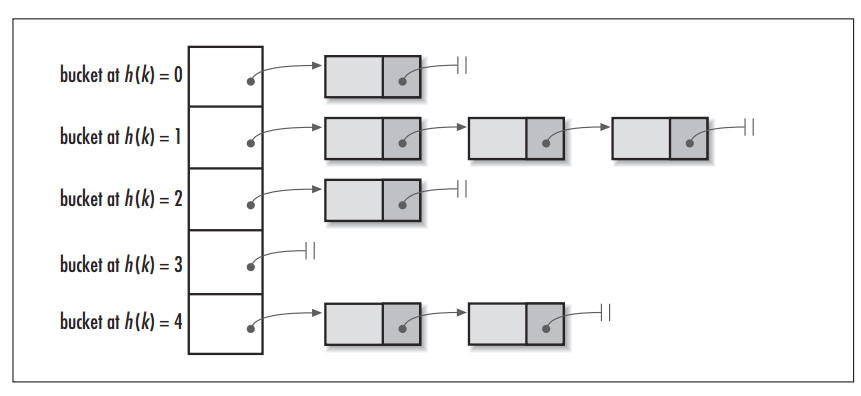
链地址法:将哈希表的每个单元作为链表的头结点,所有哈希地址为i的元素构成一个同义词链表。即发生冲突时就把该关键字链在以该单元为头结点的链表的尾部。
再哈希法:当哈希地址发生冲突用其他的函数计算另一个哈希函数地址,直到冲突不再产生为止。
建立公共溢出区:将哈希表分为基本表和溢出表两部分,发生冲突的元素都放入溢出表中。
- 数据结构
数组的特点是:寻址容易,插入和删除困难;链表的特点是:寻址困难,插入和删除容易。
- 为什么使用位运算(&)来实现取模运算(%)?
位运算(&)效率要比代替取模运算(%)高很多,主要原因是位运算直接对内存数据进行操作,不需要转成十进制。
1 | X % 2^n = X & (2^n – 1) |
性能测试
- Example JDK1.7
创建3个HashMap,分别使用默认的容量(16)、使用元素个数的一半(5千万)作为初始容量、使用元素个数(一亿)作为初始容量进行初始化。然后分别向其中put一亿个KV。
测试结果:1
2
3未初始化容量,耗时 : 14419
初始化容量5000000,耗时 : 11916
初始化容量为10000000,耗时 : 7984
参考链接
http://www.hollischuang.com/archives/2091
HashSet
一般情况下,建议使用默认大小
ConcurrentSkipListMap
ConcurrentSkipListMap 一个并发安全, 基于 skip list 实现有序存储的Map
ConcurrentSkipListMap 的存取时间是log(N),和线程数几乎无关。
在非多线程的情况下,应当尽量使用TreeMap。
参考链接
https://blog.csdn.net/guangcigeyun/article/details/8278349
TreeMap
Error
- java.util.ConcurrentModificationException
分析:当我们迭代一个ArrayList或者HashMap时,如果尝试对集合做一些修改操作(例如删除元素),可能会抛出java.util.ConcurrentModificationException的异常。
解决方案:使用ConcurrentSkipListMap;
Java BigDecimal
RoundingMode
ROUND_CEILING
向正无限大方向舍入
如果结果为正,则舍入行为类似于 RoundingMode.UP;如果结果为负,则舍入行为类似于RoundingMode.DOWN。
例如:
1.1 -> 2
5.5 -> 6
-1.1 -> -1
-2.5 -> -2
ROUND_FLOOR
向负无限大方向舍入。
如果结果为正,则舍入行为类似于 RoundingMode.DOWN;如果结果为负,则舍入行为类似于RoundingMode.UP。
例如:
5.6 -> 5
1.1 -> 1
-1.1 -> -2
-1.6 -> -2
HALF_UP
向最接近的数字方向舍入,如果与两个相邻数字的距离相等,则向上舍入。
如果被舍弃部分 >= 0.5,则舍入行为同 RoundingMode.UP;否则舍入行为同RoundingMode.DOWN。注意,此舍入模式就是通常学校里讲的四舍五入。
例如:
2.5 -> 3
1.1 -> 1
-1.0 -> -1
-1.6 -> -2
HALF_DOWN
HALF_EVEN
向最接近数字方向舍入,如果与两个相邻数字的距离相等,则向相邻的偶数舍入。
如果舍弃部分左边的数字为奇数,则舍入行为同 RoundingMode.HALF_UP;如果为偶数,则舍入行为同RoundingMode.HALF_DOWN。
注意,在重复进行一系列计算时,根据统计学,此舍入模式可以在统计上将累加错误减到最小。此舍入模式也称为“银行家舍入法”,主要在美国使用。此舍入模式类似于Java 中对float 和double 算法使用的舍入策略。
例如:
5.5 -> 6
2.5 -> 2
-2.5 -> 2
5.5 -> -5
Error
java.lang.ArithmeticException: Division impossible
replace DECIMAL128 with DECIMAL32
java.lang.ArithmeticException: Rounding necessary
设置结果小数位数小于当前位数时,如果未设置进位方式会抛出异常:java.lang.ArithmeticException: Rounding necessary,提示我们进位方式必须,当我们设置四舍五入后即可,其他方式可查看RoundingMode枚举类。
Jackson
必须设置浮点数使用BigDecimal类型
1 | ObjectMapper().enable(DeserializationFeature.USE_BIG_DECIMAL_FOR_FLOATS) |
计算出错
BigDecimal BigDecimal(double d); //不允许使用
BigDecimal BigDecimal(String s); //常用,推荐使用
static BigDecimal valueOf(double d); //常用,推荐使用
Best Practices to Handle Exceptions
Case
Don’t Catch Throwable
Throwable 是所有 exceptions 和 errors 的父类。虽然你可以在 catch 子句中使用它,但你应该永远别这样做!
如果你在 catch 子句中使用了 Throwable ,它将不仅捕获所有异常,还会捕获所有错误。这些错误是由 JVM 抛出的,用来表明不打算由应用处理的严重错误。 OutOfMemoryError 和 StackOverflowError 就是典型的例子,这两种情况都是由一些超出应用控制范围的情况导致的,无法处理。
所以,最好不要在 catch 中使用 Throwable ,除非你能确保自己处于一些特定情况下,比如你自己足以处理错误,又或被要求处理错误。
Don’t Log and Throw
That is probably the most often ignored best practice in this list. You can find lots of code snippets and even libraries in which an exception gets caught, logged and rethrown.
1 | try { |
It might feel intuitive to log an exception when it occurred and then rethrow it so that the caller can handle it appropriately. But it will write multiple error messages for the same exception.
1 | 17:44:28,945 ERROR TestExceptionHandling:65 - java.lang.NumberFormatException: For input string: "xyz" |
The additional messages also don’t add any information. As explained in best practice #4, the exception message should describe the exceptional event. And the stack trace tells you in which class, method, and line the exception was thrown.
If you need to add additional information, you should catch the exception and wrap it in a custom one. But make sure to follow best practice number 9.
1 | public void wrapException(String input) throws MyBusinessException { |
So, only catch an exception if you want to handle it. Otherwise, specify it in the method signature and let the caller take care of it.
Wrap the Exception Without Consuming it
It’s sometimes better to catch a standard exception and to wrap it into a custom one. A typical example for such an exception is an application or framework specific business exception. That allows you to add additional information and you can also implement a special handling for your exception class.
When you do that, make sure to set the original exception as the cause. The Exception class provides specific constructor methods that accept a Throwable as a parameter. Otherwise, you lose the stack trace and message of the original exception which will make it difficult to analyze the exceptional event that caused your exception.
1 | public void wrapException(String input) throws MyBusinessException { |
参考链接
https://dzone.com/articles/9-best-practices-to-handle-exceptions-in-java
Java Basic Serializer
Introduction
序列化其实可以看成是一种机制,按照一定的格式将Java对象的某状态转成介质可接受的形式,以方便存储或传输。
序列化时将Java对象相关的类信息、属性及属性值等等保存起来,反序列化时再根据这些信息构建出Java对象。而过程可能涉及到其他对象的引用,所以这里引用的对象的相关信息也要参与序列化。
将Java对象序列化为二进制文件的Java序列化技术是Java系列技术中一个较为重要的技术点,在大部分情况下,开发人员只需要了解被序列化的类需要实现Serializable接口,使用ObjectInputStream和ObjectOutputStream进行对象的读写。
序列化的作用:
- 提供一种简单又可扩展的对象保存恢复机制。
- 对于远程调用,能方便对对象进行编码和解码,就像实现对象直接传输。
- 可以将对象持久化到介质中,实现对象直接存储。
- 允许对象自定义外部存储的格式。
Attention
- 序列化保存的是对象的状态,静态变量属于类的状态,因此序列化并不保存静态变量
- SuperClass不实现Serializable接口,则不会保存SuperClass的状态变量
- 通过重写writeObject和readObject实现对敏感数据的加密和解密
- Transient关键字的作用是控制变量的序列化,在变量声明前加上该关键字,可以阻止该变量被序列化到文件中,在被反序列化后transient变量的值被设为初始值,如int型的是0,对象型的是 null。
SuerperClass Serializer
如果一个子类实现了Serializable接口而父类没有实现该接口,则在序列化子类时,子类的属性状态会被写入而父类的属性状态将不被写入。所以如果想要父类属性状态也一起参与序列化,就要让它也实现 Serializable 接口。
如果父类未实现Serializable接口,则反序列化生成的对象会再次调用父类的构造函数,以此完成对父类的初始化。所以父类属性初始值一般都是类型的默认值。
Externalizable 接口作用
Externalizable接口主要就是提供给用户自己控制序列化内容,虽然transient和ObjectStreamField能定义序列化的字段,但通过Externalizable接口则能更加灵活。
它其实继承了Serializable 接口,提供了writeExternal和readExternal两个方法,也就是在这两个方法内控制序列化和反序列化的内容。
1 | public class ExternalizableTest implements Externalizable { |
serialVersionUID
在序列化操作时,经常会看到实现了Serializable 接口的类会存在一个serialVersionUID属性,并且它是一个固定数值的静态变量。
这个属性有什么作用?其实它主要用于验证版本一致性,每个类都拥有这么一个ID,在序列化的时候会一起被写入流中,那么在反序列化的时候就被拿出来跟当前类的serialVersionUID 值进行比较,两者相同则说明版本一致,可以序列化成功,而如果不同则序列化失败。
Example 1
Case: 两个客户端A和B试图通过网络传递对象数据,A端将对象C序列化为二进制数据再传给B,B反序列化得到C。C对象的全类路径假设为com.abc.model,在A和B端都有这么一个类文件,功能代码完全一致。也都实现了Serializable接口,但是反序列化时总是提示不成功。
关键点:虚拟机是否允许反序列化,不仅取决于类路径和功能代码是否一致,还有一个非常重要的点是两个类的序列化ID是否一致(serialVersionUID)。
序列化存储规则
Example 1
1 | import java.io.* |
输出结果
1 | 42 |
误区:两次写入对象,文件大小会变为两倍的大小,反序列化时,由于从文件读取,生成了两个对象,判断相等时应该是输入false才对。
Java 序列化机制为了节省磁盘空间,具有特定的存储规则,当写入文件的为同一对象时,并不会再将对象的内容进行存储,而只是再次存储一份引用,上面增加的5字节的存储空间就是新增引用和一些控制信息的空间。
反序列化时,恢复引用关系,使得代码中的t1和t2指向唯一的对象,二者相等,输出 true。该存储规则极大的节省了存储空间。
Example 2
1 | import java.io.* |
输出
1 | 1 |
误区:写入一次以后修改对象属性值再次保存第二次,然后从result.obj中再依次读出两个对象,输出这两个对象的i属性值,因为保存的状态不一样,因此两个对象的i属性应该不同。
第一次写入对象以后,第二次再试图写的时候,虚拟机根据引用关系知道已经有一个相同对象已经写入文件,因此只保存第二次写的引用,所以读取时,都是第一次保存的对象。因此在使用一个文件多次writeObject需要特别注意这个问题。
Reference
https://www.ibm.com/developerworks/cn/java/j-lo-serial/index.html
https://juejin.im/post/5a7111535188257350518592