Distributed ID
背景
所谓全局唯一的 id 其实往往对应是生成唯一记录标识的业务需求。
这个id常常是数据库的主键,数据库上会建立聚集索引(cluster index),即在物理存储上以这个字段排序。
这个记录标识上的查询,往往又有分页或者排序的业务需求。所以往往要有一个time字段,并且在time字段上建立普通索引(non-cluster index)。
普通索引存储的是实际记录的指针,其访问效率会比聚集索引慢,如果记录标识在生成时能够基本按照时间有序,则可以省去这个time字段的索引查询。
这就引出了记录标识生成的两大核心需求:
- 全局唯一
- 趋势有序
常见生成策略
用数据库的 auto_increment 来生成
优点:
- 此方法使用数据库原有的功能,所以相对简单
- 能够保证唯一性
- 能够保证递增性
- id 之间的步长是固定且可自定义的
缺点:
- 可用性难以保证:数据库常见架构是 一主多从 + 读写分离,生成自增ID是写请求 主库挂了就玩不转了
- 扩展性差,性能有上限:因为写入是单点,数据库主库的写性能决定ID的生成性能上限,并且 难以扩展
单点批量ID生成服务
uuid / guid
优点:
- 本地生成ID,不需要进行远程调用,时延低
- 扩展性好,基本可以认为没有性能上限
缺点:
- 无法保证趋势递增
- uuid过长,往往用字符串表示,作为主键建立索引查询效率低,常见优化方案为“转化为两个uint64整数存储”或者“折半存储”(折半后不能保证唯一性)
取当前毫秒数
优点:
- 本地生成ID,不需要进行远程调用,时延低
- 生成的ID趋势递增
- 生成的ID是整数,建立索引后查询效率高
缺点:
- 如果并发量超过1000,会生成重复的ID
这个缺点要了命了,不能保证ID的唯一性。当然,使用微秒可以降低冲突概率,但每秒最多只能生成1000000个ID,再多的话就一定会冲突了,所以使用微秒并不从根本上解决问题。
使用Redis来生成id
Twitter开源的Snowflake算法
对于分布式的ID生成,以Twitter Snowflake为代表的,Flake系列算法,属于划分命名空间并行生成的一种算法,生成的数据为64bit的long型数据,在数据库中应该用大于等于64bit的数字类型的字段来保存该值,比如在MySQL中应该使用BIGINT。
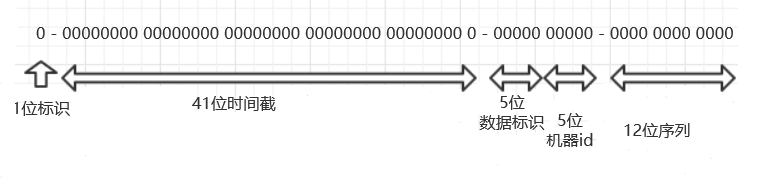
结构说明(64bit):
第一比特位保留
时间戳,41比特,从2016年11月1日零点到现在的毫秒数,可以用到2156年,100多年后才会用完
机器id,10比特,这个机器id每个业务要唯一,机器id获取的策略后面会详述
序列号,12比特,每台机器每毫秒最多产生4096个id,超过这个数的话会等到下一毫秒
特别注意,这个方案所支持的最小划分粒度是「毫秒 * 线程」,单线程(Snowflake 里对应的概念是 Worker)的每毫秒容量是12-bit,也就是接近4096。
该算法存在的问题:
依赖机器时钟,如果机器时钟回拨,会导致重复ID生成
在单机上是递增的,但是由于设计到分布式环境,每台机器上的时钟不可能完全同步,有时候会出现不是全局递增的情况(此缺点可以认为无所谓,一般分布式ID只要求趋势递增,并不会严格要求递增~90%的需求都只要求趋势递增)
Sharding-jdbc
根据机器IP获取工作进程Id,如果线上机器的IP二进制表示的最后10位不重复,建议使用此种方式,列如机器的IP为192.168.1.108,二进制表示:11000000 10101000 00000001 01101100 截取最后10位 01 01101100,转为十进制364,设置workerId为364。
注意,机器XXX.XXX.209.55,XXX.XXX.161.55转化为workid,发现都是一样的。只要workerid相同,同时在这两台机器上出现请求,就会产生重复,或者说只要线上IP末尾相同,就有可能会产生重复。
备用方案:根据机器名最后的数字编号获取工作进程编号。如果线上机器命名有统一规范,建议使用此种方式。例如,机器的 HostName 为: dangdang-db-sharding-dev-01(公司名-部门名-服务名-环境名-编号),会截取 HostName 最后的编号 01 作为工作进程编号( workId )。
美团Leaf
参考链接
Java Lock
Lock Type
- 公平锁/非公平锁
- 可重入锁
- 独享锁/共享锁
- 互斥锁/读写锁
- 乐观锁/悲观锁
- 分段锁
- 偏向锁/轻量级锁/重量级锁
- 自旋锁
公平锁/非公平锁
公平锁是指多个线程按照申请锁的顺序来获取锁。
非公平锁是指多个线程获取锁的顺序并不是按照申请锁的顺序,有可能后申请的线程比先申请的线程优先获取锁。有可能,会造成优先级反转或者饥饿现象。
对于Java ReentrantLock而言,通过构造函数指定该锁是否是公平锁,默认是非公平锁。非公平锁的优点在于吞吐量比公平锁大。对于Synchronized而言,也是一种非公平锁。由于其并不像ReentrantLock是通过AQS的来实现线程调度,所以并没有任何办法使其变成公平锁。
- Synchronized和ReentrantLock的区别
共同点:
- 协调多线程对共享对象、变量的访问
- 可重入,同一线程可以多次获得同一个锁
- 都保证了可见性和互斥性
差异点:
- ReentrantLock显示获得、释放锁,synchronized隐式获得释放锁
- ReentrantLock可响应中断、可轮回,synchronized是不可以响应中断的,为处理锁的不可用性提供了更高的灵活性
- ReentrantLock是API级别的,synchronized是JVM级别的
- ReentrantLock可以实现公平锁
- ReentrantLock通过Condition可以绑定多个条件
- 底层实现不一样, synchronized是同步阻塞,使用的是悲观并发策略,ReentrantLock是同步非阻塞,采用的是乐观并发策略
Distributed Redlock
Redlock原理
redis作者鉴于单点redis作为分布式锁的可能出现的锁数据丢失问题,提出了Redlock算法,该算法实现了比单一节点更安全、可靠的分布式锁管理(DLM)
缓存锁
使用缓存作为分布式锁,性能非常强劲,在一些不错的硬件上,redis可以每秒执行10w次,内网延迟不超过1ms,足够满足绝大部分应用的锁定需求。
redis锁定的原理是利用setnx命令,即只有在某个key不存在情况才能set成功该key,这样就达到了多个进程并发去set同一个key,只有一个进程能set成功。
仅有一个setnx命令,redis遇到的问题跟数据库锁一样,但是过期时间这一项,redis自带的expire功能可以不需要应用主动去删除锁。而且从 Redis 2.6.12 版本开始,redis的set命令直接直接设置NX和EX属性,NX即附带了setnx数据,key存在就无法插入,EX是过期属性,可以设置过期时间。这样一个命令就能原子的完成加锁和设置过期时间。
缓存锁优势是性能出色,劣势就是由于数据在内存中,一旦缓存服务宕机,锁数据就丢失了。像redis自带复制功能,可以对数据可靠性有一定的保证,但是由于复制也是异步完成的,因此依然可能出现master节点写入锁数据而未同步到slave节点的时候宕机,锁数据丢失问题。
算法
Redlock算法假设有N个redis节点,这些节点互相独立,一般设置为N=5,这N个节点运行在不同的机器上以保持物理层面的独立。
算法的步骤如下:
客户端获取当前时间,以毫秒为单位。
客户端尝试获取N个节点的锁,(每个节点获取锁的方式和前面说的缓存锁一样),N个节点以相同的key和value获取锁。客户端需要设置接口访问超时,接口超时时间需要远远小于锁超时时间,比如锁自动释放的时间是10s,那么接口超时大概设置5-50ms。这样可以在有redis节点宕机后,访问该节点时能尽快超时,而减小锁的正常使用。
客户端计算在获得锁的时候花费了多少时间,方法是用当前时间减去在步骤一获取的时间,只有客户端获得了超过3个节点的锁,而且获取锁的时间小于锁的超时时间,客户端才获得了分布式锁。
客户端获取的锁的时间为设置的锁超时时间减去步骤三计算出的获取锁花费时间。
如果客户端获取锁失败了,客户端会依次删除所有的锁。
使用Redlock算法,可以保证在挂掉最多2个节点的时候,分布式锁服务仍然能工作,这相比之前的数据库锁和缓存锁大大提高了可用性,由于redis的高效性能,分布式缓存锁性能并不比数据库锁差。
Kubernetes Pod
Pod Properties
1 | env: |
Log
https://docs.docker.com/config/containers/logging/json-file/
Install ELK on Kubernetes
ELK
Elasticsearch
Elasticsearch best-practices recommend to separate nodes in three roles:
Master nodes - intended for clustering management only, no data, no HTTP API
Client nodes - intended for client usage, no data, with HTTP API
Data nodes - intended for storing and indexing data, no HTTP API
Elasticsearch 启动时会根据配置文件中设置的集群名字(cluster.name)自动查找并加入集群。Elasctisearch 节点默认使用 9300 端口寻找集群,所以必须开启这个端口。
一个 Elasticsearch 集群中一般拥有三种角色的节点,master、data 和 client。
master:master 节点负责一些轻量级的集群操作,比如创建、删除数据索引、跟踪记录集群中节点的状态、决定数据分片(shards)在 data 节点之间的分布;
data:data 节点上保存了数据分片。它负责数据相关操作,比如分片的 CRUD,以及搜索和整合操作。这些操作都比较消耗 CPU、内存和 I/O 资源;
client:client 节点起到路由请求的作用,实际上可以看做负载均衡器。
配置文件中有两个与集群相关的配置:
node.master:默认 true。True 表示该节点是 master 节点;
node.data:默认 true。True 表示该节点时 data 节点。如果两个值都为 false,表示是 client 节点。
一个集群中不一定有 client 节点,但是肯定有 master 和 data 节点。默认第一个启动的节点是 master。Master 节点也能起到路由请求和搜索结果整合的作用,所以在小规模的集群中,无需 client 节点。但是如果集群规模很大,则有必要设置专门的 client。
参考链接
https://www.ibm.com/developerworks/cn/opensource/os-cn-elk-filebeat/index.html
Kubernetes
lasticsearch pods need for an init-container to run in privileged mode, so it can set some VM options. For that to happen, the kubelet should be running with args –allow-privileged, otherwise the init-container will fail to run.
Note
- max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]
临时生效方式,修改宿主机参数
1 | sudo sysctl -w vm.max_map_count=655360 |
永久生效方式
1 | sudo vim /etc/sysctl.conf |
- max file descriptors [4096] for elasticsearch process likely too low, increase to at least [65536]
参考链接
https://github.com/carlosedp/kubernetes-elasticsearch-cluster
JVM GC Logger
Configuation
Analyze Logger
GC格式图解
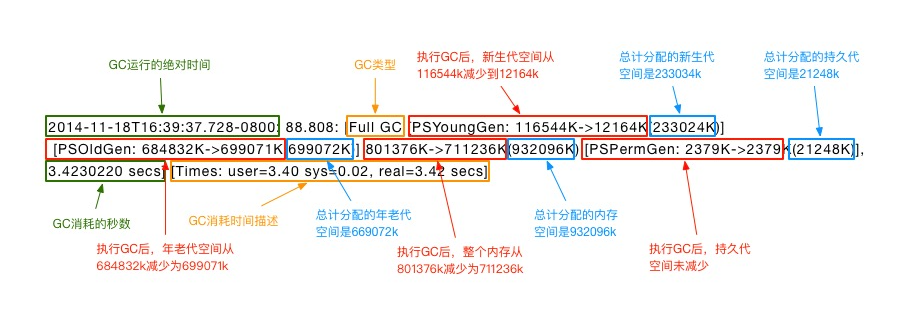
实战分析
1 | [GC pause (G1 Evacuation Pause) (young) 140.031: [G1Ergonomics (CSet Construction) start choosing CSet, _pending_cards: 19075, predicted base time: 18.50 ms, remaining time: 81.50 ms, target pause time: 100.00 ms] |
1 | [GC pause (G1 Evacuation Pause) (young) 144.865: |
Reference
https://blog.csdn.net/lijingyao8206/article/details/80566384
JVM Analazy
Visual VM
Plugin
查看DirectMemory:Buffer Pools 和 MBeans Browser
jmap
Usage
查看当前存活对象统计
1 | jmap -histo:live pid |
1 | jmap -dump:format=b,file=heap.bin pid |
jstat
使用举例
- 需要每250毫秒查询一次进程2849 垃圾收集状况,一共查询20次
1 | jstat -gc 2849 250 20 |
输出结果说明
- S0 — Heap上的 Survivor space 0 区已使用空间的百分比
- S1 — Heap上的 Survivor space 1 区已使用空间的百分比
- E — Heap上的 Eden space 区已使用空间的百分比
- O — Heap上的 Old space 区已使用空间的百分比
- P — Perm space 区已使用空间的百分比
- YGC — 从应用程序启动到采样时发生 Young GC 的次数
- YGCT– 从应用程序启动到采样时 Young GC 所用的时间(单位秒)
- FGC — 从应用程序启动到采样时发生 Full GC 的次数
- FGCT– 从应用程序启动到采样时 Full GC 所用的时间(单位秒)
- GCT — 从应用程序启动到采样时用于垃圾回收的总时间(单位秒)
- S0C: Current survivor space 0 capacity (kB).
- S1C: Current survivor space 1 capacity (kB).
- S0U: Survivor space 0 utilization (kB).
- S1U: Survivor space 1 utilization (kB).
- EC: Current eden space capacity (kB).
- EU: Eden space utilization (kB).
- OC: Current old space capacity (kB).
- OU: Old space utilization (kB).
- MC: Metaspace capacity (kB).
- MU: Metacspace utilization (kB).
- CCSC: Compressed class space capacity (kB).
- CCSU: Compressed class space used (kB).
- YGC: Number of young generation garbage collection events.
- YGCT: Young generation garbage collection time.
- FGC: Number of full GC events.
- FGCT: Full garbage collection time.
- GCT: Total garbage collection time.
jstack
Java Stack Trace,Java堆栈跟踪工具
这个命令用于查看虚拟机当前时刻的线程快照(一般是threaddump 或者 javacore文件)。线程快照就是当前虚拟机内每一条线程正在执行的方法堆栈的集合。生成线程快照的主要目的是定位线程出现长时间停顿的原因,入线程间死锁、死循环、请求外部资源导致的长时间等待都是导致线程长时间停顿的常见原因。线程出现停顿的时候通过jstack来查看各个线程的调用堆栈,就可以知道没有响应的线程到底在后台做些什么事情。
jconsole
一个java GUI监视工具,可以以图表化的形式显示各种数据。并可通过远程连接监视远程的服务器VM。用java写的GUI程序,用来监控VM,并可监控远程的VM,非常易用,而且功能非常强。命令行里打 jconsole,选则进程就可以了
docker
1 | CMD ["java", \ |
Error
Unable to open socket file: target process not responding or HotSpot VM not loaded
使用openJDK造成的,改用Oracle JDK即可