排查JVM的线程卡死
Thread Status
- NEW
- RUNNABLE
- BLOCKED
- WAITING
- TIMED_WAITING
- TERMINATED
Practice - jstack
1 | jstack -l pid |
-l:long listing. Prints additional information about locks
此时输出的日志如下:
1 | 2019-06-15 08:51:29 |
异常日志
1 | "main" #1 prio=5 os_prio=0 tid=0x00007f3fac00c000 nid=0x9 runnable [0x00007f3fb1fb2000] |
问题点:at com.anda.trading.Application.blockingUntilJournalFinish(Application.kt:188) 死循环等待。
Practice - arthas
Reference
StringTable造成YGC越来越慢,为什么?
Introduction
测试代码
1 | class StringYGC { |
JVM Options:-XX:+UseConcMarkSweepGC -XX:+PrintGCDetails -Xmx2G -Xms2G -Xmn100M
这里特意将新生代设置比较小,老生代设置比较大,让代码在执行过程中更容易突出问题来,大量做ygc,期间不做CMS GC。
1 | [GC (Allocation Failure) [ParNew: 81920K->8306K(92160K), 0.0087308 secs] 81920K->8306K(2086912K), 0.0087759 secs] [Times: user=0.06 sys=0.01, real=0.01 secs] |
从输出的Log来看,发现YGC不断发生,并且每次YGC时间不断在增长,从9ms慢慢增长到了163ms,甚至还会继续涨下去。原因是什么?
String.intern()
我们先来了解下intern方法的实现,这是String提供的一个方法,JVM提供这个方法的目的是希望对于某个同名字符串使用非常多的场景,在JVM里只保留一份,比如我们不断new String(“Hello”),其实在java heap里会有多个String的对象,并且值都是Hello,如果我们只希望内存里只保留一个Hello,或者希望我接下来用到的地方都返回同一个Hello,那就可以用String.intern这个方法了。
1 | val h1 = "Hello".intern() |
这样 h1 和 h2 都是指向内存里的同一个String对象,那JVM里到底怎么做到的呢?
intern这个方法其实是一个native方法,具体对应到JVM里的逻辑是:
1 | oop StringTable::intern(oop string, TRAPS) |
其实在JVM里存在一个叫做StringTable的数据结构,这个数据结构是一个Hashtable,在我们调用String.intern的时候其实就是先去这个StringTable里查找是否存在一个同名的项,如果存在就直接返回对应的对象,否则就往这个table里插入一项,指向这个String对象,那么再下次通过intern再来访问同名的String对象的时候,就会返回上次插入的这一项指向的String对象。
JVM里提供一个参数专门来控制这个table的size,-XX:StringTableSize,既然有这个参数,那么意味着StringTable是size是固定的。
当发生Hash碰撞的时候,你就要对其对应的桶挨个遍历,超过了100个还是没有找到对应的同名的项,那就会设置一个flag,让下次进入到safepoint的时候做一次rehash动作,尽量减少碰撞的发生,但是当恶化到一定程度的时候,其实也没啥办法啦,因为你的数据量实在太大,桶子数就那么多,那每个桶再怎么均匀也会带着一个很长的链表,所以此时我们通过修改上面的StringTableSize将桶数变大,可能会一定程度上缓解,但是如果是java代码的问题导致泄露,那就只能定位到具体的代码进行改造了。
在JDK6及之前的版本,字符串常量池是放在Perm Gen(也就是方法区)中。
在JDK7版本,字符串常量池被移到了堆中了。至于为什么移到堆内,大概是由于方法区的内存空间太小了。
StringTable为什么会影响YGC
YGC中对StringTable处理的具体代码:
1 | if (!_process_strong_tasks->is_task_claimed(SH_PS_StringTable_oops_do)) { |
因为YGC过程不涉及到对perm做回收,因此collecting_perm_gen是false,而JavaObjectsInPerm默认情况下也是false,表示String.intern返回的字符串是不是在perm里分配,如果是false,表示是在heap里分配的,因此StringTable指向的字符串是在heap里分配的,所以YGC过程需要对StringTable做扫描,以保证处于新生代的String代码不会被回收掉。
设想一下如果StringTable非常庞大,那是不是意味着YGC过程扫描的时间也会变长呢?这也就是解释了为什么StringTable会影响YGC了,
另外一个问题是StringTable什么时候清理?
YGC过程不会对StringTable做清理,这也就是我们demo里的情况会让Stringtable越来越大,但是在FGC或者CMS GC的过程中会对StringTable进行清理。
如何证明?命令 jmap -histo:live
触发FGC
输出SringTable统计信息
JVM Option:-XX:+PrintStringTableStatistics
Testing Code:
1 | class StringYGC { |
GC日志:
1 | [GC (Allocation Failure) [ParNew: 81920K->8477K(92160K), 0.0069494 secs] 81920K->8477K(2086912K), 0.0069858 secs] [Times: user=0.05 sys=0.01, real=0.01 secs] |
SymbolTable statistics:
1 | StringTable statistics: |
- Average bucket size:bucket中LinkedList的平均size。
- Maximum bucket size:表示bucket中LinkedList最大的size。
- Number of entries:Hashtable的entry数量。
- Number of buckets:bucket数量。
Average bucket size越大,说明Hashtable碰撞越严重,由于bucket数量固定为60013,随着StringTable添加的引用越来越多,碰撞越来越严重,YGC时间越来越长。
Comparing Testing
GC日志:
1 | [GC (Allocation Failure) [ParNew: 81920K->8819K(92160K), 0.0083969 secs] 81920K->8819K(2086912K), 0.0084334 secs] [Times: user=0.06 sys=0.00, real=0.01 secs] |
1 | StringTable statistics: |
对比上面的结果,Average bucket size降低很明显。
设置StringTableSize一个合适的值,即bucket数量为期望的数量后,碰撞的概率明显降低,由Average bucket size和Maximum bucket size的值明显小于未配置StringTableSize参数时的值可知,且YGC时间也明显降低。另外, 最好通过BTrace分析是哪里频繁调用String.intern(), 确实String.intern()没有滥用的前提下, 再增大StringTableSize的值。
为什么StringTable不能扩大?
既然StringTable是Hashtable数据结构,那为什么不能自己通过rehash扩大bucket数量来提高性能呢?JVM中StringTable的rehash有点不一样,JVM中StringTable的rehash不会扩大bucket数量,而是在bucket不变的前提下,通过一个新的seed尝试摊平每个bucket中LinkedList的长度。
rehash大概是一个如下图所示的过程,rehash前后bucket数量不变,这是重点:
假设reash前数据分布(23,4,8,2,1,5)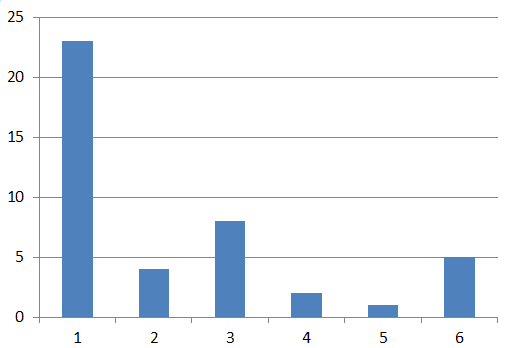
假设reash前数据分布(6,8,8,9,5,7)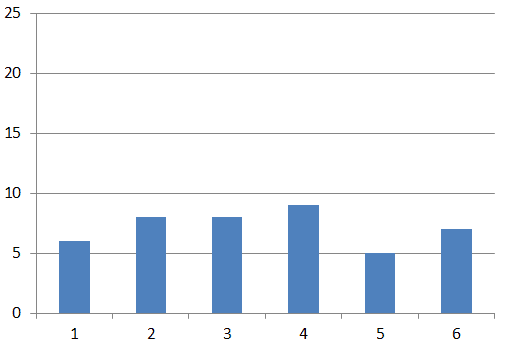
Disable Jackson String.intern
1 | // com.fasterxml.jackson.core.util.InternCache.intern(InternCache.java:45) |
jackson之所以用intern去处理,本来是想节省点cache的内存,没想到业务场景是每次都不一样的字符串,这样直接就导致了String.intern后StringTable的大小暴涨,所以在这种场景中,这样做反而得不偿失,还好jackson代码支持通过接口来把调用intern的部分关掉。
CANONICALIZE_FIELD_NAMES (default: true)
- Means that once name String is decoded from input (byte or char stream), it will be added in a symbol table, to reduce overhead of decoding same name next time it is seen (by any parser constructed by same factory)
INTERN_FIELD_NAMES (default: true)
- If canonicalization is enabled, this feature determines whether String decoded is also interned (using String.intern()) or not – doing that can help further improve deserialization performance since identity comparison may be used.
- If names are unlikely to repeat, or if sheer number of distinct names is huge (in tens of thousands or above), it may make sense to disable this feature.
Disable using String.intern() method:
1 | val factory = JsonFactory().disable(JsonFactory.Feature.INTERN_FIELD_NAMES) |
Reference
http://lovestblog.cn/blog/2016/11/06/string-intern/
https://juejin.im/post/5ab99afff265da23a2291dee
Refresh:https://coolshell.cn/articles/9606.html
https://www.jianshu.com/p/5524fce8b08f
http://hellojava.info/?p=514
Jackson触发的String.intern():https://www.cnblogs.com/halberts/p/7473857.html
JVM YGC
Introduction
预备知识
otSpot JVM把年轻代分为了三部分:1个Eden区和2个Survivor区(分别叫from和to)。默认比例为8:1,为啥默认会是这个比例,接下来我们会聊到。一般情况下,新创建的对象都会被分配到Eden区(一些大对象特殊处理),这些对象经过第一次YGC后,如果仍然存活,将会被移到Survivor区。对象在Survivor区中每熬过一次YGC,年龄就会增加1岁,当它的年龄增加到一定程度时,就会被移动到年老代中。
因为年轻代中的对象基本都是朝生夕死的(80%以上),所以在年轻代的垃圾回收算法使用的是复制算法,复制算法的基本思想就是将内存分为两块,每次只用其中一块,当这一块内存用完,就将还活着的对象复制到另外一块上面。复制算法不会产生内存碎片。
在GC开始的时候,对象只会存在于Eden区和名为“From”的Survivor区,Survivor区“To”是空的。紧接着进行GC,Eden区中所有存活的对象都会被复制到“To”,而在“From”区中,仍存活的对象会根据他们的年龄值来决定去向。年龄达到一定值(年龄阈值,可以通过-XX:MaxTenuringThreshold来设置)的对象会被移动到年老代中,没有达到阈值的对象会被复制到“To”区域。经过这次GC后,Eden区和From区已经被清空。这个时候,“From”和“To”会交换他们的角色,也就是新的“To”就是上次GC前的“From”,新的“From”就是上次GC前的“To”。不管怎样,都会保证名为To的Survivor区域是空的。YGC会一直重复这样的过程,直到“To”区被填满,“To”区被填满之后,会将所有对象移动到年老代中。
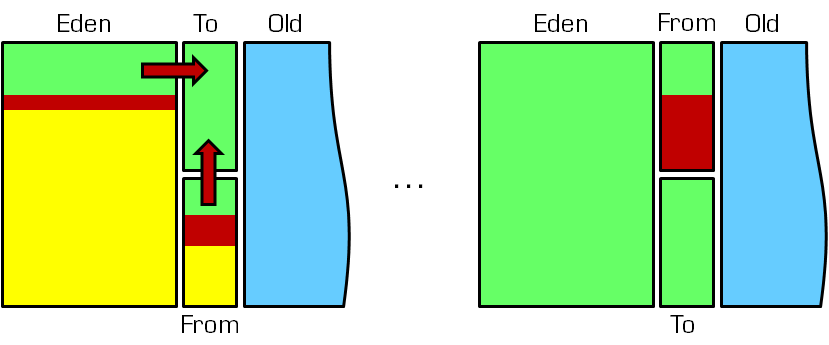
YGC - Young GC
YGC是JVM GC当前最为频繁的一种GC,一个高并发的服务在运行期间,会进行大量的YGC,发生YGC时,会进行STW,一般时间都很短,除非碰到YGC时,存在大量的存活对象需要进行拷贝。
一次YGC过程主要分成两个步骤:
- 查找GC Roots,拷贝所引用的对象到 to 区;
- 递归遍历上一步中查找到的对象,并拷贝其所引用的对象到 to 区,当然可能会存在自然晋升,或者因为 to 区空间不足引起的提前晋升的情况;
Find GC Roots
YGC的第一步根据GC Roots找出第一批活跃的对象,Hotspot中通过 gch->gen_process_strong_roots 方法实现
Serial GC源代码为例

- 在黄色框的实现中,SharedHeap::process_strong_roots()扫描了所有一定是GC Roots的内存区域;
- 红色框中的实现逻辑对于YGC来说是没有意义的,因为level=0,Hotspot中唯一用到这个地方的只有CMS GC实现,默认只收集old generation,所以需要扫描young generation作为它的Strong root;
- 如果一个old generation的对象引用了young generation,那么这个old generation的对象肯定也属于Strong root的一部分,这部分逻辑并没有在process_strong_roots中实现,而是在绿色框中实现了,其中rem_set中保存了old generation中dirty card的对应区域,每次对象的拷贝移动都会检查一下是否产生了新的跨代引用,比如有对象晋升到了old generation,而该对象还引用了young generation的对象,这种情况下会把相应的card置为dirty,下次YGC的时候只会扫描dirty card所指内存的对象,避免扫描所有的old generation对象。
process_strong_roots的实现,主要包括了以下东西:
- Universe类中所引用的一些必须存活的对象 Universe::oops_do(roots)
- 所有JNI Handles JNIHandles::oops_do(roots)
- 所有线程的栈 Threads::oops_do(roots, code_roots)
- 所有被Synchronize锁持有的对象 ObjectSynchronizer::oops_do(roots)
- VM内实现的MBean所持有的对象 Management::oops_do(roots)
- JVMTI所持有的对象 JvmtiExport::oops_do(roots)
- (可选)所有已加载的类 或 所有已加载的系统类 SystemDictionary::oops_do(roots)
- (可选)所有驻留字符串(StringTable) StringTable::oops_do(roots)
- (可选)代码缓存(CodeCache) CodeCache::scavenge_root_nmethods_do(code_roots)
- (可选)PermGen的remember set所记录的存在跨代引用的区域 rem_set()->younger_refs_iterate(perm_gen(), perm_blk)
注意:YGC在执行时只收集young generation,不收集old generation和perm generation,并不会做类的卸载行为,所以上述可选部分都作为Strong root,但是在FGC时就不会当作Strong root了。
Recurse Roots
在查找GC Roots的步骤中,已经找出了第一批存活的对象,这些存活对象可能在 to-space,也有可能直接晋升到了 old generation,这些区域都是需要进行遍历的,保证所有的活跃对象都能存活下来。
遍历过程的实现由FastEvacuateFollowersClosure类的do_void方法完成,这是一个*-Closure 方式命名的类,实现如下:

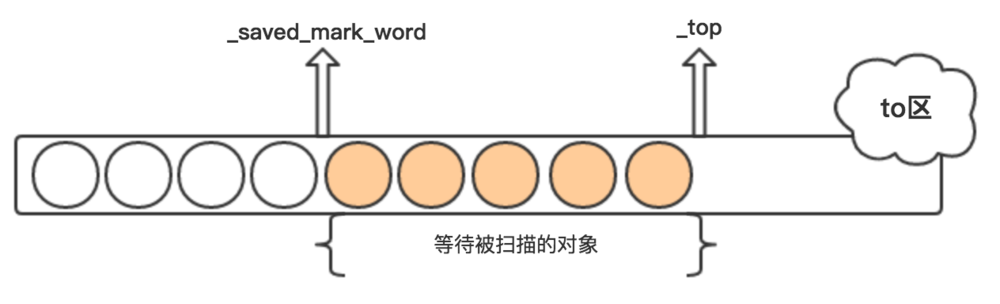
每个内存区域都有两个指针变量,分别是 _saved_mark_word 和 _top,其中_saved_mark_word 指向当前遍历对象的位置,_top指向当前内存区域可分配的位置,其中_saved_mark_word 到 _top之间的对象是已拷贝,但未扫描的对象。
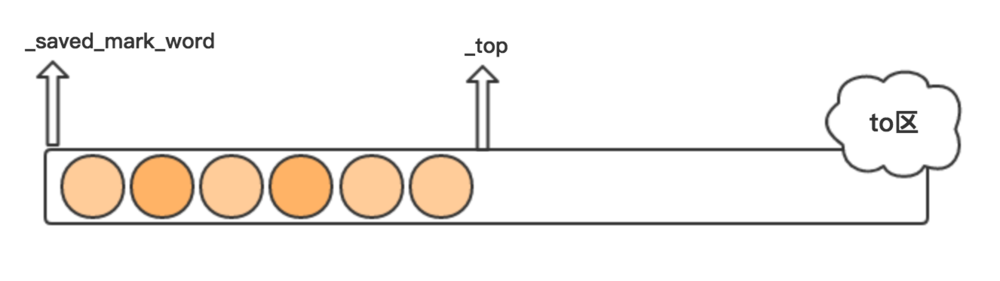
GC Roots引用的对象拷贝完成后,to-space的_saved_mark_word和_top的状态如上图所示,假设期间没有对象晋升到old generation。每次扫描一个对象,_saved_mark_word会往前移动,期间也有新的对象会被拷贝到to-space,_top也会往前移动,直到_saved_mark_word追上_top,说明to-space的对象都已经遍历完成。
其中while循环条件 while (!_gch->no_allocs_since_save_marks(_level),就是在判断各个内存代中的_saved_mark_word是否已经追到_top,如果还没有追上,就执行_gch->oop_since_save_marks_iterate进行遍历,实现如下:
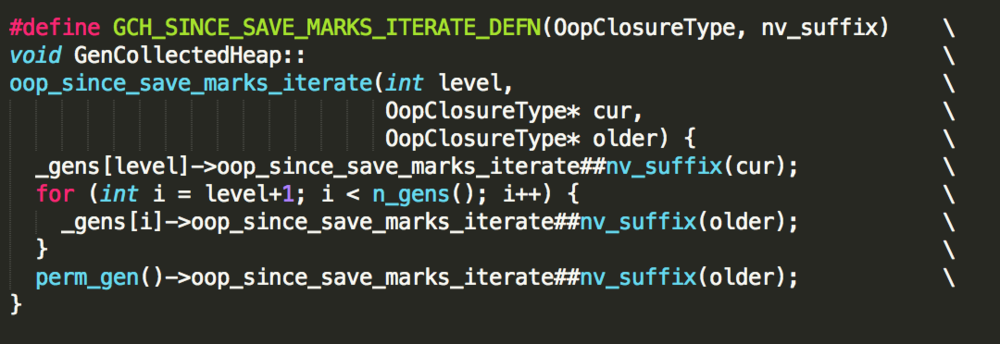
to-space对象的遍历实现:
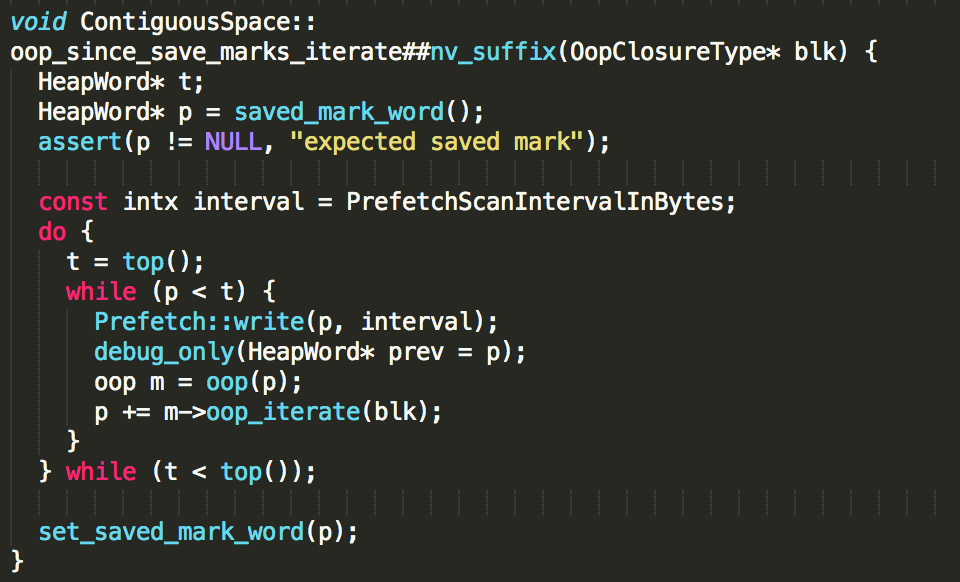
这里的blk变量是传递过来的FastScanClosure回调函数,oop_iterate方法会遍历该对象的所有引用,并调用回调函数的do_oop_work方法处理这里引用所指向的对象。
do_oop_work的实现:

在FastScanClosure回调函数的do_oop_work方法实现中,红框的是重要的部分,因为可能存在多个对象共同引用一个对象,所以在遍历过程中,可能会遇到已经处理过的对象,如果遇到这样的对象,就不会再次进行复制了,如果该对象没有被拷贝过,则调用 copy_to_survivor_space 方法拷贝对象到to-space或者晋升到old generation,这里提一下ParNew的实现,因为是并发执行的,所以可能存在多个线程拷贝了同一个对象到to-space,不过通过原子操作,保证了只有一个对象是有效的。
copy_to_survivor_space 的实现:
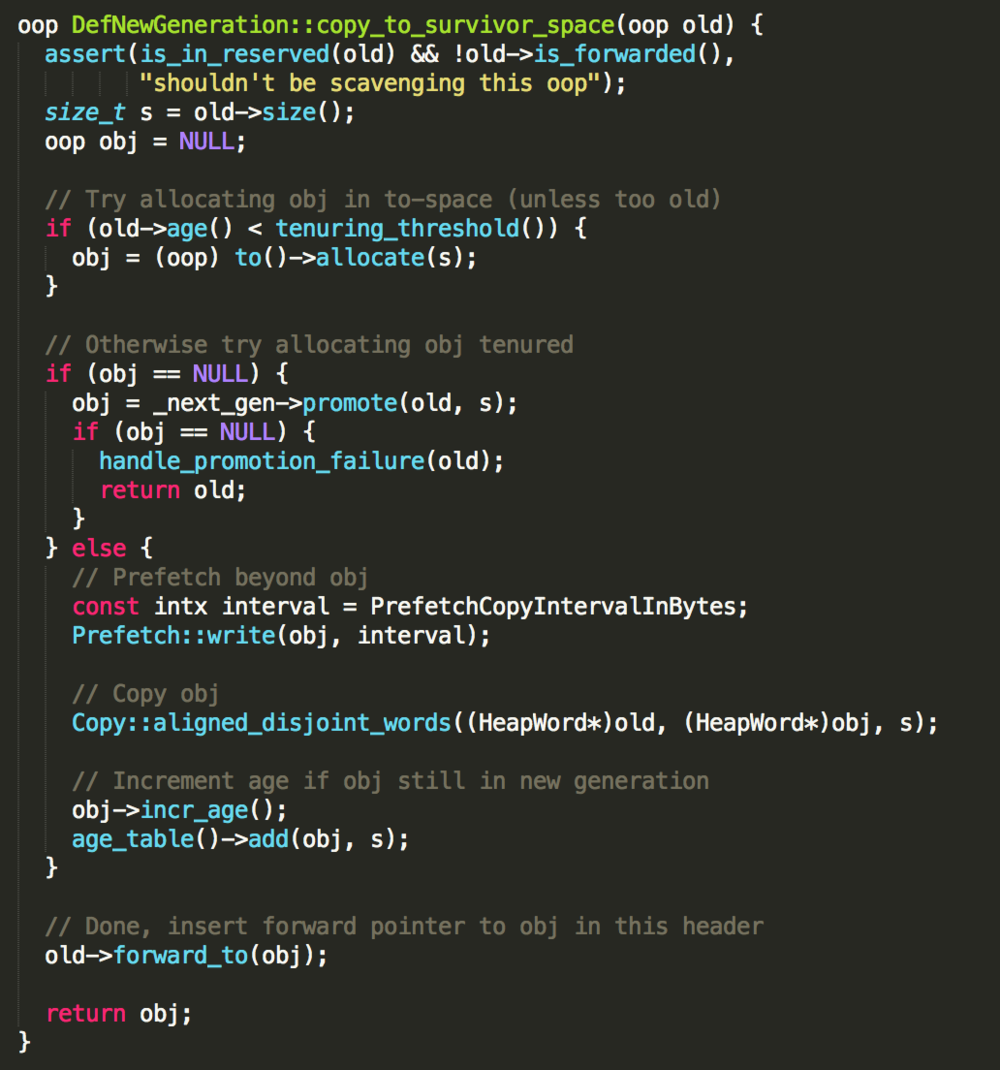
拷贝对象的目标空间不一定是to-space,也有可能是old generation,如果一个对象经历了很多次YGC,会从young generation直接晋升到old generation,为了记录对象经历的YGC次数,在对象头的mark word 数据结构中有一个位置记录着对象的YGC次数,也叫对象的年龄,如果扫描到的对象,其年龄小于某个阈值(tenuring threshold),该对象会被拷贝到to-space,并增加该对象的年龄,同时to-space的_top指针也会往后移动,这个新对象等待着被扫描。
Full GC 和 YGC 触发条件
YGC:对新生代堆进行GC。频率比较高,因为大部分对象的存活寿命较短,在新生代里被回收。性能耗费较小。
YGC触发条件:
- edn空间不足
FGC:全堆范围的GC。默认堆空间使用到达80%(可调整)的时候会触发FGC。
FGC触发条件:
- old空间不足;
- perm空间不足;
- 显示调用System.gc(),包括RMI等的定时触发;
- YGC时的悲观策略;
- dump live的内存信息时(jmap –dump:live);
- heap dump。
悲观策略:当准备要触发一次 young GC时,如果发现统计数据说之前 young GC的平均晋升大小比目前的 old gen剩余的空间大,则不会触发young GC而是转为触发 full GC。
因为HotSpot VM的GC里,除了垃圾回收器 CMS 的 concurrent collection 之外,其他能收集 old gen 的GC都会同时收集整个GC堆,包括young gen,所以不需要事先准备一次单独的young GC。
Reference
http://ifeve.com/jvm-yong-generation/
https://www.jianshu.com/p/9af1a63a33c3
https://juejin.im/post/5b8d2a5551882542ba1ddcf8
https://www.zhihu.com/question/41922036/answer/93079526
Java Queue
Introduction
Interface
1 | /** |
Classification
- PriorityQueue
- PriorityBlockingQueue
- Deque
- ArrayDeque:ArrayDeque是一个循环队列,它使用数组实现的Deque,底层是数组。
- BlockingQueue
- ArrayBlockingQueue
- LinkedBlockingQueue
- SynchronousQueue
Summary
- 当 Deque 当做 Queue 队列使用时(FIFO),添加元素是添加到队尾,删除时删除的是头部元素。
- 当 Deque 当做 Stack 栈用(LIFO)。这时入栈、出栈元素都是在双端队列的头部进行。
- ArrayDeque不是线程安全的。 当作为栈使用时,性能比Stack好;当作为队列使用时,性能比LinkedList好。
- ArrayBlockingQueue 底层是数组,有界队列,如果我们要使用生产者-消费者模式,这是非常好的选择。
- LinkedBlockingQueue 底层是链表,可以当做无界和有界队列来使用,所以大家不要以为它就是无界队列。
- SynchronousQueue 本身不带有空间来存储任何元素,使用上可以选择公平模式和非公平模式。
- PriorityBlockingQueue 是无界队列,基于数组,数据结构为二叉堆,数组第一个也是树的根节点总是最小值。
BlockingQueue
ArrayBlockingQueue
ArrayBlockingQueue 是 BlockingQueue 接口的有界队列实现类,底层采用数组来实现。其并发控制采用可重入锁来控制,不管是插入操作还是读取操作,都需要获取到锁才能进行操作。
核心属性
1 | // 用于存放元素的数组 |
核心原理
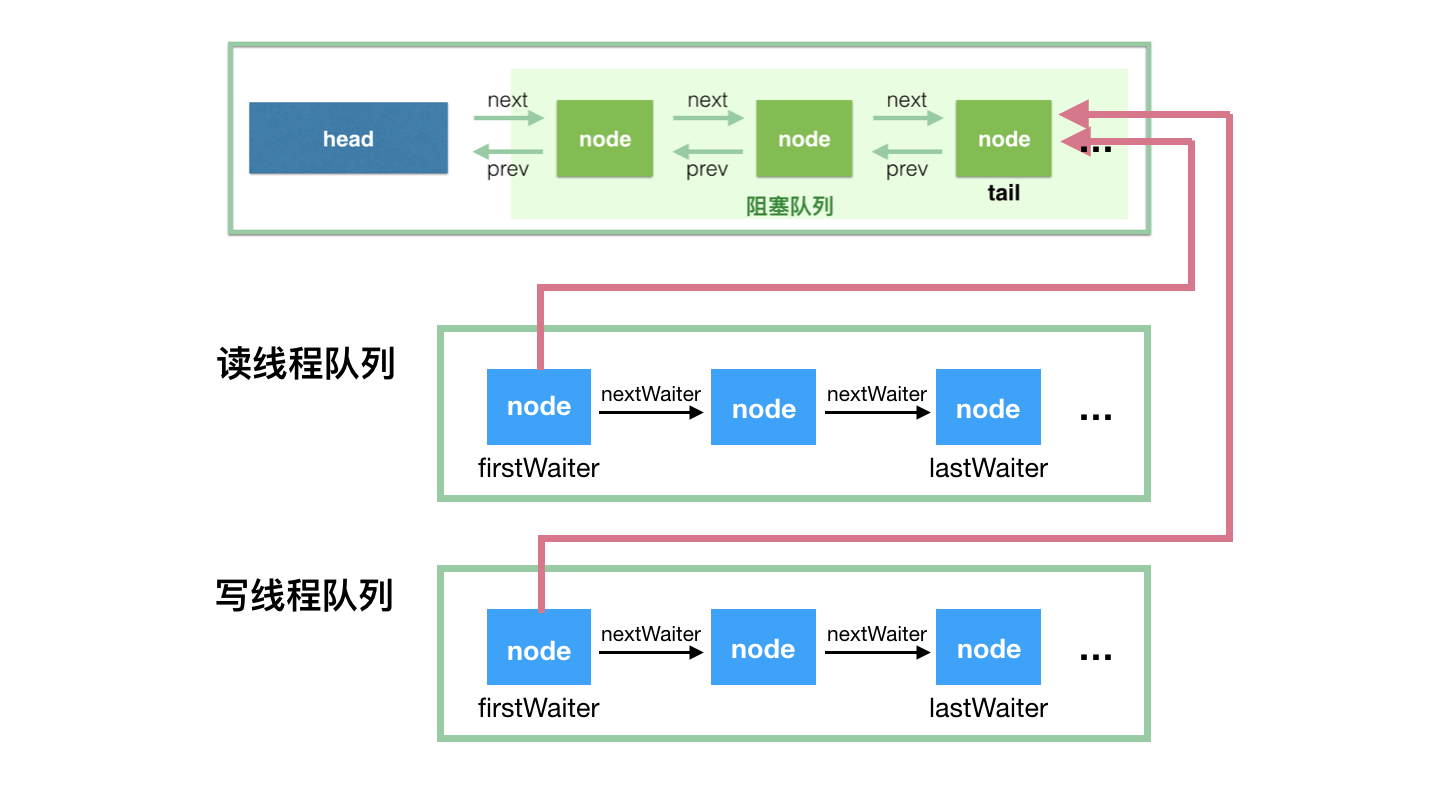
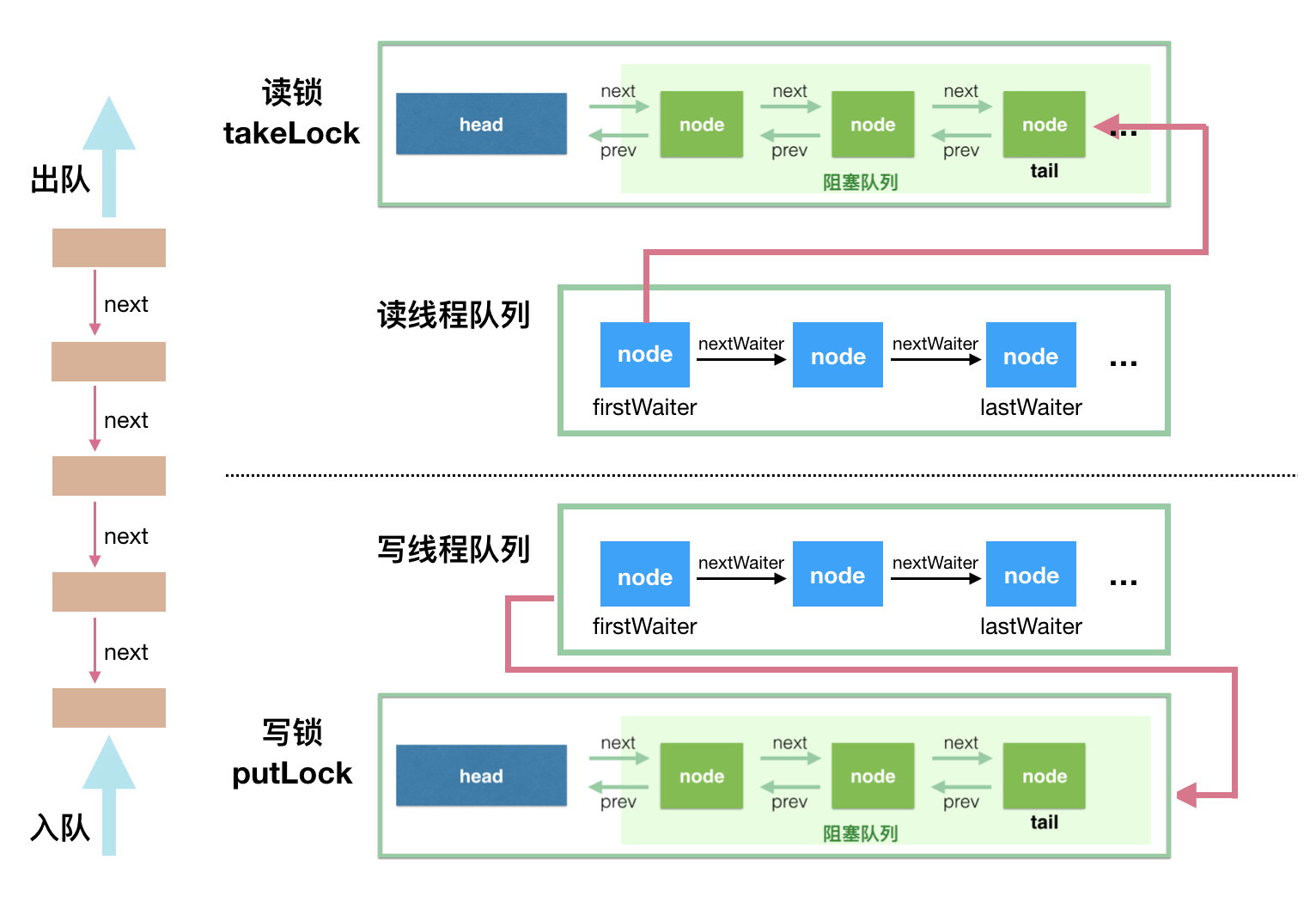
ArrayBlockingQueue 实现并发同步的原理就是,读操作和写操作都需要获取到 AQS 独占锁才能进行操作。
如果队列为空,这个时候读操作的线程进入到读线程队列排队,等待写线程写入新的元素,然后写线程唤醒读线程队列的第一个等待线程。如果队列已满,这个时候写操作的线程进入到写线程队列排队,等待读线程将队列元素移除腾出空间,然后唤醒写线程队列的第一个等待线程。
构造函数可选参数:
- 队列容量,其限制了队列中最多允许的元素个数;
- 指定独占锁是公平锁还是非公平锁。非公平锁的吞吐量比较高,公平锁可以保证每次都是等待最久的线程获取到锁;
- 可以指定用一个集合来初始化,将此集合中的元素在构造方法期间就先添加到队列中。
LinkedBlockingQueue
底层基于单向链表实现的阻塞队列,可以当做无界队列也可以当做有界队列来使用。
核心属性
1 | // 队列容量 |
ReentrantLock与Condition使用说明:
takeLock 和 notEmpty 搭配:如果要获取(take)一个元素,需要获取 takeLock 锁,但是获取了锁还不够,如果队列此时为空,还需要队列不为空(notEmpty)这个条件(Condition)。
putLock 和 notFull 搭配:如果要插入(put)一个元素,需要获取 putLock 锁,但是获取了锁还不够,如果队列此时已满,还需要队列不是满的(notFull)这个条件(Condition)。
SynchronousQueue
不像ArrayBlockingQueue或LinkedListBlockingQueue,SynchronousQueue内部并没有数据缓存空间,你不能调用peek()方法来看队列中是否有数据元素,因为数据元素只有当你试着取走的时候才可能存在,不取走而只想偷窥一下是不行的,当然遍历这个队列的操作也是不允许的。队列头元素是第一个排队要插入数据的线程,而不是要交换的数据。数据是在配对的生产者和消费者线程之间直接传递的,并不会将数据缓冲数据到队列中。可以这样来理解:生产者和消费者互相等待对方,握手,然后一起离开。
虽然说是队列,但是 SynchronousQueue 的队列其实是虚的,其不提供任何空间(一个都没有)来存储元素。数据必须从某个写线程交给某个读线程,而不是写到某个队列中等待被消费。
在开发中比较少使用到 SynchronousQueue 这个类,不过它在线程池的实现类 ScheduledThreadPoolExecutor 中得到了应用。Executors.newCachedThreadPool()就使用了SynchronousQueue,这个线程池根据需要(新任务到来时)创建新的线程,如果有空闲线程则会重复使用,线程空闲了60秒后会被回收。
核心原理
1 | // 写入值 |
写操作 put(E o) 和读操作 take() 都是调用 Transferer.transfer(…) 方法,区别在于第一个参数是否为 null 值。
transfer 的设计思路,其基本算法如下:
当调用这个方法时,如果队列是空的,或者队列中的节点和当前的线程操作类型一致(如当前操作是 put 操作,而队列中的元素也都是写线程)。这种情况下,将当前线程加入到等待队列即可。
如果队列中有等待节点,而且与当前操作可以匹配(如队列中都是读操作线程,当前线程是写操作线程,反之亦然)。这种情况下,匹配等待队列的队头,出队,返回相应数据。
示例图说明
- 前提条件:公平模式,初始化情况下,TransferQueue的状态
- put线程1执行操作put(1),由于当前没有配对的消费线程,所以线程1入队列,自旋一小会后睡眠等待。
- put线程2执行操作put(2),由于当前没有配对的消费线程,所以线程2入队列,自旋一小会后睡眠等待。
- 这时候taker线程执行操作taker(1),由于tail指向put2线程,put线程2跟take线程1配对了(put一take),这时take1线程不需要入队,但是请注意了,这时候,要唤醒的线程并不是put线程2,而是put线程1。put线程1被唤醒,take线程1的take()方法返回了put线程1的数据,这样就实现了线程间的一对一通信,这时候内部状态如下:
公平策略总结下来就是:队尾匹配队头出队。
SynchronousQueue的实现模型。总结下来就是:队尾匹配队头出队,先进先出,体现公平原则。
PriorityBlockingQueue
带排序的 BlockingQueue 实现,其并发控制采用的是 ReentrantLock,队列为无界队列(ArrayBlockingQueue 是有界队列,LinkedBlockingQueue 也可以通过在构造函数中传入 capacity 指定队列最大的容量,但是 PriorityBlockingQueue 只能指定初始的队列大小,后面插入元素的时候,如果空间不够的话会自动扩容)。
简单地说,它就是 PriorityQueue 的线程安全版本。不可以插入 null 值,同时,插入队列的对象必须是可比较大小的(comparable),否则报 ClassCastException 异常。它的插入操作 put 方法不会 block,因为它是无界队列(take 方法在队列为空的时候会阻塞)。
核心属性
1 | // 构造方法中,如果不指定大小的话,默认大小为 11 |
此类实现了 Collection 和 Iterator 接口中的所有接口方法,对其对象进行迭代并遍历时,不能保证有序性。
如果你想要实现有序遍历,建议采用 Arrays.sort(queue.toArray()) 进行处理。PriorityBlockingQueue 提供了 drainTo 方法用于将部分或全部元素有序地填充(准确说是转移,会删除原队列中的元素)到另一个集合中。
还有一个需要说明的是,如果两个对象的优先级相同(compare 方法返回 0),此队列并不保证它们之间的顺序。
PriorityBlockingQueue 使用了基于数组的二叉堆来存放元素,所有的 public 方法采用同一个 lock 进行并发控制。
Reference
Git Flow QuickStart
Introduction
Git Flow重点解决的是由于源代码在开发过程中的各种冲突导致开发活动混乱的问题。因此,Git flow可以很好的于各种现有开发模型相结合使用。
Git Flow模型中定义了主分支和辅助分支两类分支。其中主分支用于组织与软件开发、部署相关的活动;辅助分支组织为了解决特定的问题而进行的各种开发活动。
分支类型说明:
feature: 用于日常的功能开发,一般一个功能分支代表一个功能,一般一个功能分支代表一个功能。
继承分支:develop,合并分支:develop,命名规则:任何名字除了master, develop, release-, hotfix-
release:当需要发布新版本时使用,主要用于测试。可在此分支上直接开发功能,修复bug,但务必同时合并到develop和master。
继承分支:develop,合并分支:develop master,命名规则:release-*
hotfix:用于修复线上的bug,务必同时合并到develop和master。
继承分支:master,合并分支:develop master,命名规则:hotfix-*
Git Flow Tools
Feature Branch
创建 feature 分支
1
2
3
4
5
6
7
8
9
10
11
12git flow feature start login
#### output #####
Switched to a new branch 'feature/login'
Summary of actions:
- A new branch 'feature/login' was created, based on 'develop'
- You are now on branch 'feature/login'
Now, start committing on your feature. When done, use:
git flow feature finish login完成 feature 分支
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15git flow feature finish login
#### output #####
Switched to branch 'develop'
Updating d2df03b..85d1933
Fast-forward
login.java | 0
1 file changed, 0 insertions(+), 0 deletions(-)
create mode 100644 login.java
Deleted branch feature/login (was 85d1933).
Summary of actions:
- The feature branch 'feature/login' was merged into 'develop'
- Feature branch 'feature/login' has been removed
- You are now on branch 'develop'
此时,本地feature/login已经被删除,同时代码合并到了本地的develop分支。
如果想在github上保留feature/login,则需要手动push该分支。
Release Branch
创建 release 分支
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15git flow release start 1.13.1
#### output #####
Switched to a new branch 'release/1.13.1'
Summary of actions:
- A new branch 'release/1.13.1' was created, based on 'develop'
- You are now on branch 'release/1.13.1'
Follow-up actions:
- Bump the version number now!
- Start committing last-minute fixes in preparing your release
- When done, run:
git flow release finish '1.13.1'完成 release 分支
1
2
3
4
5
6
7
8
9
10
11git flow release finish '1.13.1'
#### output #####
Deleted branch release/1.13.1 (was 85d1933).
Summary of actions:
- Latest objects have been fetched from 'origin'
- Release branch has been merged into 'master'
- The release was tagged '1.13.1'
- Release branch has been back-merged into 'develop'
- Release branch 'release/1.13.1' has been deleted
完成release 1.13.1后,本地release 1.13.1会被删除 ,release代码会自动合并到本地 master 分支。
如果想在github上保留release 1.13.1,则需要手动push该分支。
- Push Tag
1 | git push origin 1.13.1 |
Hotfix Branch
1 | # 创建hotfix分支 |
和release分支一样,提交时也会自动打上tag。
Reference
http://www.ruanyifeng.com/blog/2015/12/git-workflow.html
https://juejin.im/post/5c3e9b6df265da616c65d685
What's MTU and MSS?
Introduction
如果发送的TCP报文段很长的话,会在发送时发生分段,在接收端进行重组,同样IP数据报在长度超过一定值时也会发生分片,在接收端再将分片重组。
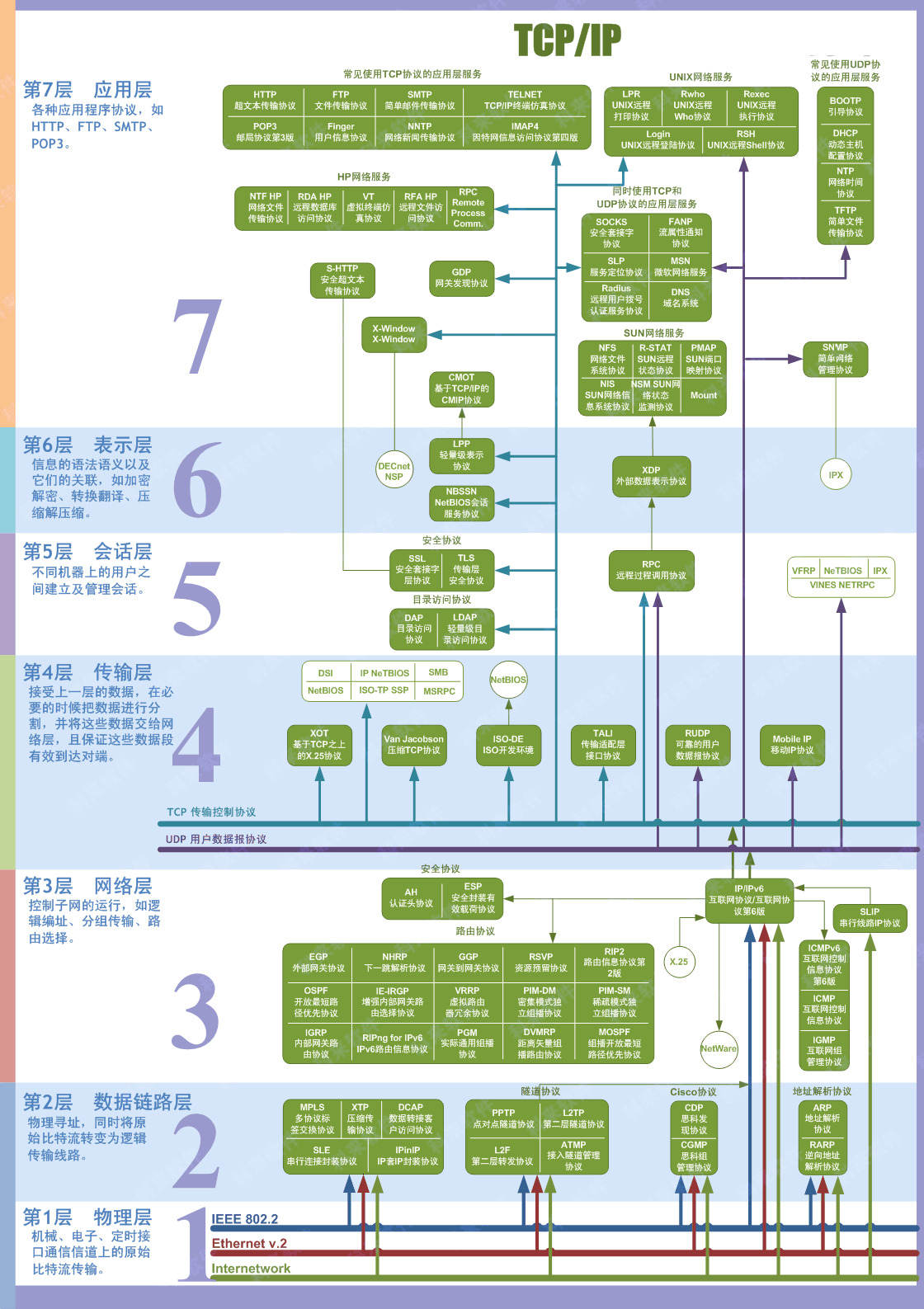
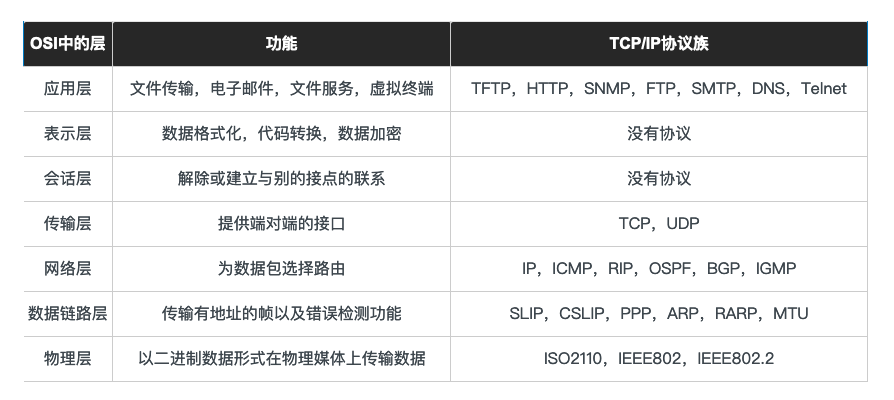
在7层网络协议中,MTU是数据链路层的概念。MTU限制的是数据链路层的payload,也就是上层协议的大小,例如IP,ICMP等。
MTU - Maximum Transmission Unit
MTU 是链路层中的网络对数据帧的一个限制,依然以以太网为例,MTU为1500个字节。一个IP数据报在以太网中传输,如果它的长度大于该MTU值,就要进行分片传输,使得每片数据报的长度小于MTU。分片传输的IP数据报不一定按序到达,但IP首部中的信息能让这些数据报片按序组装。IP数据报的分片与重组是在网络层进完成的。
如何确定 UDP 包的数据大小?
- 在链路层,由以太网的物理特性决定了数据帧的长度为 46+18 ~ 1500+18,其中的18是数据帧的头和尾,也就是说数据帧的内容最大为1500(不包括帧头和帧尾),即MTU(Maximum Transmission Unit)为1500;
- 在网络层,因为IP包的首部要占用20字节,所以这时MTU为1500-20=1480;
- 在传输层,对于UDP包的首部要占用8字节,所以这时MTU为1480-8=1472;
所以,在应用层,你的Data最大长度为1472。当我们的UDP包中的数据多于MTU(1472)时,发送方的IP层需要分片进行传输,而在接收方IP层则需要进行数据报重组,由于UDP是不可靠的传输协议,如果分片丢失导致重组失败,将导致UDP数据包被丢弃。
从上面的分析来看,在普通的局域网环境下,UDP的数据最大为1472字节最好(避免分片重组)。但在网络编程中,Internet中的路由器可能有设置成不同的值(小于默认值),Internet上的标准MTU值为576,所以Internet的UDP编程时数据长度最好在576-20-8=548字节以内。
如何查看路由的MTU值?
Theory:ping程序使用ICMP报文,ICMP报文首部占8字节,IP数据报首部占20字节,因此在数据大小基础上加上28字节为MTU值。
- Windows: ping -f -l 1472 192.168.0.1
- Linux: ping -c 1 -M do -s 1470 216.58.204.110
MSS - Maxitum Segment Size
MSS是TCP里的一个概念。MSS是TCP数据包每次能够传输的最大数据分段,TCP报文段的长度大于MSS时,要进行分段传输。
TCP协议在建立连接的时候通常要协商双方的MSS值,每一方都有用于通告它期望接收的MSS选项(MSS选项只出现在SYN报文段中,即TCP三次握手的前两次)。MSS的值一般为MTU值减去两个首部大小(需要减去IP数据包包头的大小20Bytes和TCP数据段的包头20Bytes),所以如果用链路层以太网,MSS的值往往为1460。而Internet上标准的MTU(最小的MTU,链路层网络为x2.5时)为576,那么如果不设置,则MSS的默认值就为536个字节。很多时候,MSS的值最好取512的倍数。TCP报文段的分段与重组是在运输层完成的。
MSS = MTU - IP首部大小 - TCP首部大小。
小结
TCP分段的原因是MSS,IP分片的原因是MTU,由于一直有MSS <= MTU,很明显,分段后的每一段TCP报文段再加上IP首部后的长度不可能超过MTU,因此也就不需要在网络层进行IP分片了。因此TCP报文段很少会发生IP分片的情况。
再来看UDP数据报,由于UDP数据报不会自己进行分段,因此当长度超过了MTU时,会在网络层进行IP分片。同样,ICMP(在网络层中)同样会出现IP分片情况。
另外,IP数据报分片后,只有第一片带有UDP首部或ICMP首部,其余的分片只有IP头部,到了端点后根据IP头部中的信息再网络层进行重组。而TCP报文段的每个分段中都有TCP首部,到了端点后根据TCP首部的信息在传输层进行重组。IP数据报分片后,只有到达目的地后才进行重组,而不是向其他网络协议,在下一站就要进行重组。
最后一点,对IP分片的数据报来说,即使只丢失一片数据也要重新传整个数据报(既然有重传,说明运输层使用的是具有重传功能的协议,如TCP协议)。这是因为IP层本身没有超时重传机制,则由更高层(比如TCP)来负责超时和重传。当来自TCP报文段的某一段(在IP数据报的某一片中)丢失后,TCP在超时后会重发整个TCP报文段,该报文段对应于一份IP数据报(可能有多个IP分片),没有办法只重传数据报中的一个数据分片。
Example
举一个最简单的场景,你在家用自己的笔记本上网,用的是路由器,路由器连接电信网络,然后访问了www.baidu.com,从你的笔记本出发的一个以太网数据帧总共经过了以下路径:
1 | 1500 1500 1500 |
假设现在我把笔记本的MTU最大值设置成了1700,然后发送了一个超大的ip数据包(2000),这时候在以外网传输的时候会被拆成2个包,一个1700,一个300,然后加上头信息进行传输。
1 | 1700 1500 1500 |
路由器接收到了一个1700的帧,发现大于自己设置的最大值:1500,如果IP包DF标志位为1,也就是不允许分包,那么路由器直接就把这个包丢弃了,根本就不会到达电信机房,也就到不了服务器了,所以,到这里我们就会发现,MTU其实就是在每一个节点的管控值,只要是大于这个值的数据帧,要么选择分片,要么直接丢弃。
为什么MTU通常设置为1500?
其实一个标准的以太网数据帧大小是:1518,头信息有14字节,尾部校验和FCS占了4字节,所以真正留给上层协议传输数据的大小就是:1518 - 14 - 4 = 1500,那么,1518这个值又是从哪里来的呢?
假设取一个更大的MTU值会怎么样?
假设MTU值和IP数据包大小一致,一个IP数据包的大小是:65535,那么加上以太网帧头和为,一个以太网帧的大小就是:65535 + 14 + 4 = 65553,看起来似乎很完美,发送方也不需要拆包,接收方也不需要重组。
那么假设我们现在的带宽是:100Mbps,因为以太网帧是传输中的最小可识别单元,再往下就是0101所对应的光信号了,所以我们的一条带宽同时只能发送一个以太网帧。如果同时发送多个,那么对端就无法重组成一个以太网帧了,在100Mbps的带宽中(假设中间没有损耗),我们计算一下发送这一帧需要的时间:
( 65553 8 ) / ( 100 1024 * 1024 ) ≈ 0.005(s)
在100M网络下传输一帧就需要5ms,也就是说这5ms其他进程发送不了任何数据。如果是早先的电话拨号,网速只有2M的情况下:
( 65553 8 ) / ( 2 1024 * 1024 ) ≈ 0.100(s)
100ms,这简直是噩梦。其实这就像红绿灯,时间要设置合理,交替通行,不然同一个方向如果一直是绿灯,那么另一个方向就要堵成翔了。
MTU值既然大了不行,那把MTU的值设置小一点可以么?
假设MTU值设置为100,那么单个帧传输的时间,在2Mbps带宽下需要:
( 100 8 ) / ( 2 1024 1024 ) 1000 ≈ 5(ms)
时间上已经能接受了,问题在于,不管MTU设置为多少,以太网头帧尾大小是固定的,都是14 + 4,所以在MTU为100的时候,一个以太网帧的传输效率为:
( 100 - 14 - 4 ) / 100 = 82%
写成公式就是:( T - 14 - 4 ) / T,当T趋于无穷大的时候,效率接近100%,也就是MTU的值越大,传输效率最高,但是基于上一点传输时间的问题,来个折中的选择吧,既然头加尾是18,那就凑个整来个1500,总大小就是1518,传输效率:
1500 / 1518 = 98.8%
100Mbps传输时间:( 1518 8 ) / ( 100 1024 1024 ) 1000 = 0.11(ms)
2Mbps传输时间:( 1518 8 ) / ( 2 1024 1024 ) 1000 = 5.79(ms)
至于MUT的值最少是64,这个值是因为和以太网帧在半双工下的碰撞有关。
Reference
https://www.zhihu.com/question/31460305
什么是MTU: https://www.vps234.com/vps-mtu-config-tutorials/
GCP and AWS MTU: http://www.cloudnetworkstuff.com/index.php/2018/04/19/multicloud-path-mtu-aws-gcp/
关于网络编程中MTU、TCP、UDP优化配置的一些总结: https://www.cnblogs.com/maowang1991/archive/2013/04/15/3022955.html
How select a best jwt cryptographic algorithm
Introduction
The common data security concerns:
- Integrity: That data has not been tampered with
- Authenticity: That the origin of the data can be verified
- Non-repudiation: The origin of the data must be verifiable by others
- Confidentiality: That data is kept secret from unauthorised parties and processes
Digital signatures
Key Type
- RSA
- EC
- OKP
Algorithms
- RSA signature with PKCS #1 and SHA-2: RS256 RS384 RS512
- RSA PSS signature with SHA-2: PS256
- EC DSA signature with SHA-2:
- Edwards-curve DSA signature with SHA-2:
RSA、DSA、ECDSA 三者的区别
EdDSA与ECDSA 的区别
ECDSA签名算法的安全性是比较依赖于安全的随机数生成算法的,如果随机数算法存在问题,使用了相同的k进行签名,那么攻击者是可以根据签名信息恢复私钥的,历史上也出过几次这样的事故,比如10年索尼的PS3私钥遭破解以及12年受Java某随机数生成库的影响造成的比特币被盗事件。所以说ECDSA签名在设计上还是存在一些问题的, 这也激励了新的EdDSA算法的出现。
EdDSA签名算法由Schnorr签名发展变化而来,可以在RFC8032中看到它的定义实现,由曲线和参数的选择不同又可以划分为Ed25519和Ed448算法,顾命思义,它们两分别是基于curve25519和curve448曲线,一般用的比较多的是Ed25519算法,相比Ed448而言运算速度要更快,秘钥与签名空间也较小,二者的使用场景还是有点区别。
Ed25519所使用的曲线由curve25519变换而来,curve25519是蒙哥马利曲线,经过变换得到Ed25519使用的扭爱德华曲线edwards25519,curve25519曲线的安全性是非常高的。
EdDSA的运算速度也比ECDSA算法要快很多,优势可以说是非常明显的,门罗币和zcash等加密货币已经将算法切换到了EdDSA了,目前其也被确认为下一代椭圆曲线算法。
Reference
https://connect2id.com/products/nimbus-jose-jwt/algorithm-selection-guide
https://security.stackexchange.com/questions/194830/recommended-asymmetric-algorithms-for-jwt
数字签名算法介绍和区别: https://zhuanlan.zhihu.com/p/33195438
算法性能测试: https://zhuanlan.zhihu.com/p/27615345
针对EdDSA的fault attack: https://www.anquanke.com/post/id/167018
ECDSA Digital Signature Verification in Java: https://metamug.com/article/sign-verify-digital-signature-ecdsa-java.html
Google Implementation Libary: https://github.com/google/tink
JVM NewRatio与SurvivorRatio
Introduction
-XX:NewRatio:新生代(Eden + 2*S)与老年代(不包括永久区)的比值。假如设置为4,4表示新生代:老年代 = 1:4,意思是老年代占 4/5。

-XX:SurvivorRatio:2个Survivor区和Eden区的比值,假如设置为8,8表示两个Survivor:Eden = 2:8,每个Survivor占 1/10。
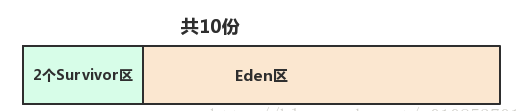
如何确定 NewRatio 和 SurvivorRatio 的最优值
JVM Options:-server -Xmx4g -Xms4g -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+ExplicitGCInvokesConcurrent -XX:NewRatio=1 -XX:SurvivorRatio=5 -XX:MetaspaceSize=32m -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -verbose:gc -Xloggc:/opt/logs/gc/gc.lo
初始化GC
1 | 2.459: [CMS-concurrent-mark: 0.001/0.001 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] |
- 新生代大小:1797568 KB = 1755.43 MB,当前已经占用 1108516 KB = 1082 MB;
[GC (Allocation Failure)
1 | [GC (Allocation Failure) 938.900: [ParNew: 1507180K->7820K(1797568K), 0.0121347 secs] 1594391K->95047K(3894720K), 0.0122274 secs] [Times: user=0.05 sys=0.00, real=0.01 secs] |
- [GC与[Full GC:表示GC类型;
- [ParNew: 1507180K->7820K(1797568K):[ParNew表示GC发生的区域,显示的区域与使用的GC收集器密切相关。1507180K 表示收集前该内存区域(新生代)已经使用的容量,820K(1797568K)表示GC后该内存区域已使用容量(该内存区域总容量)
- 1594391K->95047K(3894720K):表示GC前堆已使用容量->GC后堆已使用容量(堆总容量)
- 估算出老年大大小:3894720K - 1507180K = 2387540K = 2331.58 MB
433.231: [GC (Allocation Failure) 433.231: [ParNew: 2255562K->8497K(2696384K), 0.0112992 secs] 2342952K->95887K(3744960K), 0.0114044 secs] [Times: user=0.08 sys=0.00, real=0.01 secs]
老年代大小 = 1 GB
Reference
Kuberntes CPU Management Policies on Node
Introduction
CPU Management Policies
By default, the kubelet uses CFS quota to enforce pod CPU limits. When the node runs many CPU-bound pods, the workload can move to different CPU cores depending on whether the pod is throttled and which CPU cores are available at scheduling time. Many workloads are not sensitive to this migration and thus work fine without any intervention.
CFS:The Completely Fair Scheduler (CFS) is a process scheduler which was merged into the 2.6.23 (October 2007) release of the Linux kernel and is the default scheduler. It handles CPU resource allocation for executing processes, and aims to maximize overall CPU utilization while also maximizing interactive performance.
There are two supported policies:
- none: the default, which represents the existing scheduling behavior.
- static: allows pods with certain resource characteristics to be granted increased CPU affinity and exclusivity on the node.
The CPU manager periodically writes resource updates through the CRI in order to reconcile in-memory CPU assignments with cgroupfs. The reconcile frequency is set through a new Kubelet configuration value –cpu-manager-reconcile-period. If not specified, it defaults to the same duration as –node-status-update-frequency
None policy
The none policy explicitly enables the existing default CPU affinity scheme, providing no affinity beyond what the OS scheduler does automatically. Limits on CPU usage for Guaranteed pods are enforced using CFS quota.
Static policy
The static policy allows containers in Guaranteed pods with integer CPU requests access to exclusive CPUs on the node. This exclusivity is enforced using the cpuset cgroup controller.
Usage
Case: BestEffort
This pod runs in the BestEffort QoS class because no resource requests or limits are specified. It runs in the shared pool.
1 | spec: |
Case: Burstable
- This pod runs in the Burstable QoS class because resource requests do not equal limits and the cpu quantity is not specified. It runs in the shared pool.
1 | spec: |
- This pod runs in the Burstable QoS class because resource requests do not equal limits. It runs in the shared pool.
1 | spec: |
Case: Guaranteed
- This pod runs in the Guaranteed QoS class because requests are equal to limits. And the container’s resource limit for the CPU resource is an integer greater than or equal to one. The nginx container is granted 2 exclusive CPUs.
1 | spec: |
- This pod runs in the Guaranteed QoS class because requests are equal to limits. But the container’s resource limit for the CPU resource is a fraction. It runs in the shared pool.
1 | spec: |
- This pod runs in the Guaranteed QoS class because only limits are specified and requests are set equal to limits when not explicitly specified. And the container’s resource limit for the CPU resource is an integer greater than or equal to one. The nginx container is granted 2 exclusive CPUs.
1 | spec: |
Reference
https://en.wikipedia.org/wiki/Completely_Fair_Scheduler
https://kubernetes.io/docs/tasks/administer-cluster/cpu-management-policies/