Introduction
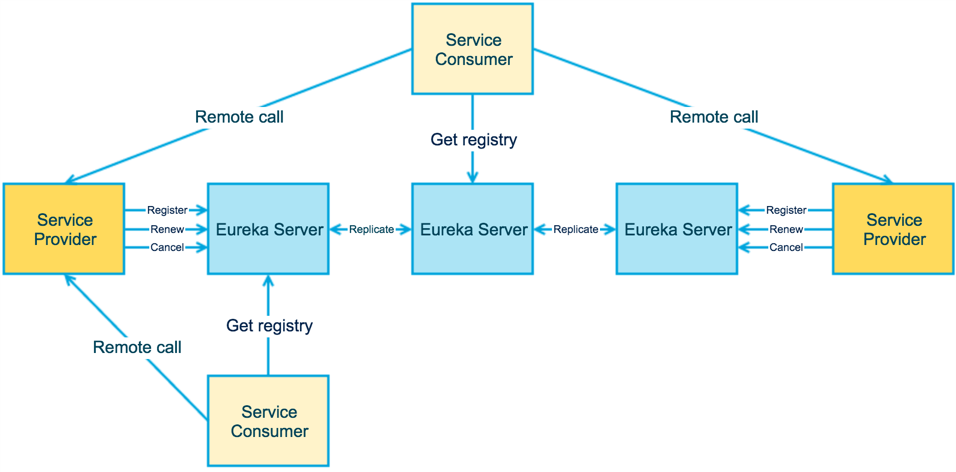
Eureka包含两个组件:Eureka Server和Eureka Client。
- Eureka Server 提供服务注册服务,各个节点启动后会在 Eureka Server 中进行注册,这样 EurekaServer 中的服务注册表中将会存储所有可用服务节点的信息,服务节点的信息可以在界面中直观的看到。
- Eureka Client 是一个java客户端,用于简化与 Eureka Server 的交互,客户端同时也就是一个内置的、使用轮询(round-robin)负载算法的负载均衡器。
CAP
从 CAP 理论看,Eureka 是一个 AP 系统,优先保证可用性A 和 分区容错性P,不保证强一致性C,只保证最终一致性,因此在架构中设计了较多缓存。
Feature:
- Eureka 不持久化缓存,重启后内存数据丢失;
- Eureka 通过增量更新注册信息,只关心瞬时状态;
- Eureka 提供客户端缓存,宁可返回某服务5分钟之前可用的服务器列表信息,也不能因为暂时的网络故障而找不到可用的服务器,满足 CAP 中的 AP。
Eureka Server
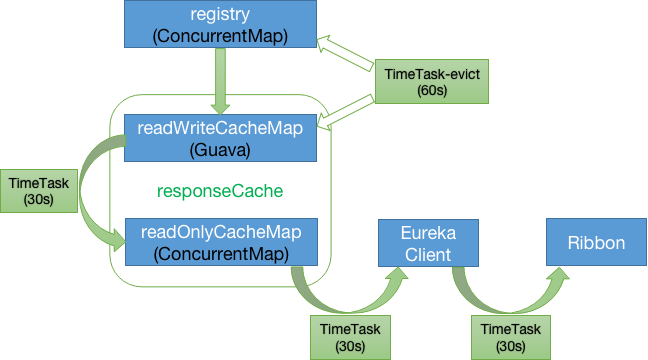
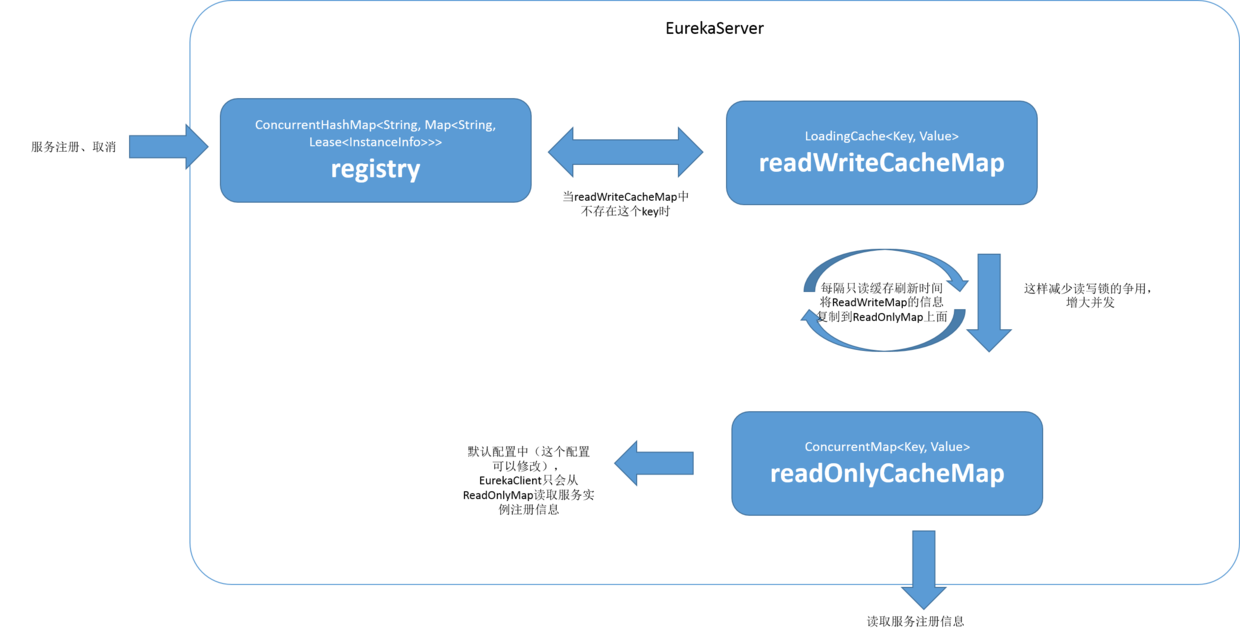
Eureka Server 存在三个变量(三级缓存机制):
- registry(ConcurrentHashMap):实时更新,类 AbstractInstanceRegistry 成员变量,UI 端请求的是这里的服务注册信息。
- readWriteCacheMap(Guava Cache/LoadingCache):实时更新,类 ResponseCacheImpl 成员变量,缓存时间 180 秒。
- readOnlyCacheMap(ConcurrentHashMap):周期更新,类 ResponseCacheImpl 成员变量,默认每30s从 readWriteCacheMap 更新,Eureka client 默认从这里更新服务注册信息,可配置直接从 readWriteCacheMap 更新
Eureka Server 通过上面的三个变量来保存服务注册信息。默认情况下定时任务每 30s 将 readWriteCacheMap 同步至 readOnlyCacheMap,每 60s 清理超过 90s 未续约的节点,Eureka Client 每 30s 从 readOnlyCacheMap 更新服务注册信息,而 UI 则从 registry 更新服务注册信息。
Association attributes:
- eureka.instance.lease-expiration-duration-in-seconds:Server 至上一次收到 Client 的心跳之后,等待下一次心跳的超时时间,在这个时间内若没收到下一次心跳,则将移除该 Instance。
默认为90秒;
如果该值太大,则很可能将流量转发过去的时候,该instance已经不存活了;
如果该值设置太小了,则instance则很可能因为临时的网络抖动而被摘除掉;
该值至少应该大于leaseRenewalIntervalInSeconds
eureka.server.enable-self-preservation:是否开启自我保护模式,默认为true。
- eureka.server.eviction-interval-timer-in-ms:Server 清理无效节点的时间间隔,默认60000毫秒,即60秒。
- eureka.server.useReadOnlyResponseCache:是否使用 readOnlyCacheMap,默认为true。
- eureka.server.responseCacheUpdateIntervalMs:readWriteCacheMap 更新至 readOnlyCacheMap 周期,默认30s。
- eureka.server.responseCacheAutoExpirationInSeconds:Server 缓存readWriteCacheMap失效时间,缓存默认180s。
Eureka Client
Eureka Client存在两种角色:服务提供者和服务消费者,作为服务消费者一般配合Ribbon或Feign(Feign内部使用Ribbon)使用。
Eureka Client启动后,作为服务提供者立即向 Server 注册,默认情况下每30s续约(renew);作为服务消费者立即向 Server 全量更新服务注册信息,默认情况下每30s增量更新服务注册信息;Ribbon 延时1s向 Client 获取使用的服务注册信息,默认每30s更新使用的服务注册信息,只保存状态为UP的服务。
Association attributes:
- eureka.instance.lease-renewal-interval-in-seconds:Client 发送心跳给 Server 端的频率,默认为30秒。如果该instance实现了 HealthCheckCallback,并决定让自己 unavailable 的话,则该 Instance 也不会接收到流量。
- eureka.client.registry-fetch-interval-seconds:Client 间隔多久去拉取服务注册信息,默认为30秒,对于 api-gateway,如果要迅速获取服务注册状态,可以缩小该值,比如5秒。
- eureka.client.registryFetchIntervalSeconds:Client 增量更新周期,默认30s(正常情况下增量更新,超时或与 Server 端不一致等情况则全量更新)。
- ribbon.ServerListRefreshInterval:Ribbon 更新周期,默认30s。
Process:
- EurekaClient 第一次全量拉取,定时增量拉取应用服务实例信息,保存在缓存中:
- EurekaClient 增量拉取失败,或者增量拉取之后对比 hashcode 发现不一致,就会执行全量拉取,这样避免了网络某时段分片带来的问题;
- 对于服务调用,如果涉及到 ribbon 负载均衡,那么 ribbon 对于这个实例列表也有自己的缓存,这个缓存定时从 EurekaClient 的缓存更新;
Registry And Discovery
如果 Server-A 向 Server-B 节点单向注册,则 Server-A 视 Server-B 为 peer Server-A 接受的数据会同步给 Server-B,但 Server-B 接受的数据不会同步给 Server-A。
Registry Process:
- 将实例注册信息放入或者更新 Registry:
- 实例注册信息加入最近修改的记录队列;
- 主动让 Response 缓存失效;
Unregister Service Process:
- 从 Registry 中剔除这个实例;
- 将实例注册信息加入最近修改的记录队列;
- 主动让 Response 缓存失效;
Peer to Peer Communication
Eureka clients tries to talk to Eureka Server in the same zone. If there are problems talking with the server or if the server does not exist in the same zone, the clients fail over to the servers in the other zones.
Once the server starts receiving traffic, all of the operations that is performed on the server is replicated to all of the peer nodes that the server knows about. If an operation fails for some reason, the information is reconciled(一致) on the next heartbeat that also gets replicated between servers.
When the Eureka server comes up, it tries to get all of the instance registry information from a neighboring node. If there is a problem getting the information from a node, the server tries all of the peers before it gives up. If the server is able to successfully get all of the instances, it sets the renewal threshold that it should be receiving based on that information. If any time, the renewals(续期) falls below the percent configured for that value (below 85% within 15 mins), the server stops expiring instances to protect the current instance registry information.
In Netflix, the above safeguard is called as self-preservation mode and is primarily used as a protection in scenarios where there is a network partition between a group of clients and the Eureka Server. In these scenarios, the server tries to protect the information it already has. There may be scenarios in case of a mass outage(中断) that this may cause the clients to get the instances that do not exist anymore. The clients must make sure they are resilient(能复原的) to eureka server returning an instance that is non-existent or un-responsive. The best protection in these scenarios is to timeout quickly and try other servers.
默认配置下服务消费者最长感知时间
正常上线
数据流:readWrite -> readOnly -> Client -> Ribbon
预估:30(readOnly) + 30(Client) + 30(Ribbon) = 90s
正常下线
数据流:readWrite -> readOnly -> Client -> Ribbon
预估:30(readOnly) + 30(Client Fetch) + 30(Ribbon) = 90s
服务正常下线(kill或kill -15杀死进程)会给进程善后机会,DiscoveryClient.shutdown() 将向 Server 更新自身状态为 DOWN,然后发送 DELETE 请求注销自己,registry 和 readWriteCacheMap 实时更新,故UI将不再显示该服务实例。
SpringBoot 下线是否会默认调用 DiscoveryClient.shutdown()?
非正常下线
预估:90(LeaseExpiration)*2 + 30(readOnly) + 30(Client Fetch) + 30(Ribbon) = 270s
服务非正常下线(kill -9杀死进程或进程崩溃)不会触发 DiscoveryClient.shutdown() 方法,Eureka Server 将依赖每60s清理超过90s未续约服务从 registry 和 readWriteCacheMap 中删除该服务实例。
优化配置
Server Configuration1
2
3
4
5
6
7
8
9
10
11
12## 中小规模下,自我保护模式坑比好处多,所以关闭它
eureka.server.enableSelfPreservation=false
## 心跳阈值计算周期,如果开启自我保护模式,可以改一下这个配置
## eureka.server.renewalThresholdUpdateIntervalMs=120000
## 主动失效检测间隔,配置成5秒
eureka.server.evictionIntervalTimerInMs=5000
## 心跳间隔,5秒
eureka.instance.leaseRenewalIntervalInSeconds=5
## 没有心跳的淘汰时间,10秒
eureka.instance.leaseExpirationDurationInSeconds=10
## 禁用readOnlyCacheMap
eureka.server.useReadOnlyResponseCache=false
Client Configuration1
2
3
4
5
6
7
8## 心跳间隔,5秒
eureka.instance.leaseRenewalIntervalInSeconds=5
## 没有心跳的淘汰时间,10秒
eureka.instance.leaseExpirationDurationInSeconds=10
# 定时刷新本地缓存时间
eureka.client.registryFetchIntervalSeconds=5
# ribbon缓存时间
ribbon.ServerListRefreshInterval=2000
- 禁用 readOnlyCacheMap,直接从 readWriteCacheMap 获取信息;
- 禁用 Self Preservation Mode;
- Heartbeat 时间间隔为5秒;
- Heartbeat 超时时间间隔为10秒;
- Client 获取服务列表信息间隔为5秒;
- ribbon 缓存刷新时间为2秒;
经过优化配置后:
- 正常上下线预估:5(Client Fetch) + 2(Ribbon) = 7秒;
- 异常下线预估(最坏情况)):10(LeaseExpiration)*2 + 5(Evict) + 5(Client Fetch) + 2(Ribbon) = 32秒
Self Preservation Mode
Eureka servers will enter self preservation mode if they detect that a larger than expected number of registered clients have terminated their connections in an ungraceful way, and are pending eviction at the same time.
This is done to ensure catastrophic network events do not wipe out eureka registry data, and having this be propagated downstream to all clients.
When in self preservation mode, eureka servers will stop eviction of all instances until either:
- the number of heartbeat renewals it sees is back above the expected threshold;
- self preservation is disabled;
默认情况下,如果 Eureka Server 在一定时间内没有接收到某个微服务实例的心跳,Eureka Server 将会注销该实例(默认90秒)。但是当网络分区故障发生时,微服务与 Eureka Server 之间无法正常通信,以上行为可能变得非常危险了——因为微服务本身其实是健康的,此时本不应该注销这个微服务。
Eureka Server 通过“自我保护模式”来解决这个问题——当 Eureka Server 节点在短时间内丢失过多客户端时(可能发生了网络分区故障),那么这个节点就会进入自我保护模式。一旦进入该模式,Eureka Server 就会保护服务注册表中的信息,不再删除服务注册表中的数据(也就是不会注销任何微服务)。当网络故障恢复后,该 Eureka Server 节点会自动退出自我保护模式。
认情况下,如果在15分钟内超过 85% 的客户端节点都没有正常的心跳,那么 Eureka 就认为客户端与注册中心出现了网络故障(比如网络故障或频繁的启动关闭客户端),Eureka Server 自动进入自我保护模式。不再剔除任何服务,当网络故障恢复后,该节点自动退出自我保护模式。
1 | eureka: |
自我保护模式是一种对网络异常的安全保护措施。使用自我保护模式让Eureka集群更加的健壮、稳定。
API-Gateway 实现服务下线实时感知
以Spring Cloud Zuul网关为例,网关作为Eureka Client保存了服务注册信息,服务消费者通过网关将请求转发给服务提供者,只需要做到服务提供者下线时通知网关在自己保存的服务列表中使该服务失效。为了保持网关的独立性,可实现一个独立服务接收下线通知并协调网关集群。
在 Kubernetes 集群中,可监听 Pod 事件来协调服务的上下线。
目前服务发现主要有两种模式:
- 客户端发现:客户端负责决定可用服务实例的网络地址,并且在集群中对请求负载均衡, 客户端访问服务登记表,也就是一个可用服务的数据库,然后客户端使用一种负载均衡算法选择一个可用的服务实例然后发起请求。
- 服务端发现:客户端通过负载均衡器向服务注册中心发起请求,负载均衡器查询服务注册中心,将每个请求路由到可用的服务实例上。
Zuul 与 Eureka 的配合
Eureka Server 为注册中心,Zuul 相对于 Eureka Server 来说是 Eureka Client,Zuul 会把 Eureka Server 端服务列表缓存到本地,并以定时任务的形式更新服务列表,同时 Zuul 通过本地列表发现其它服务,使用 Ribbon 实现客户端负载均衡。
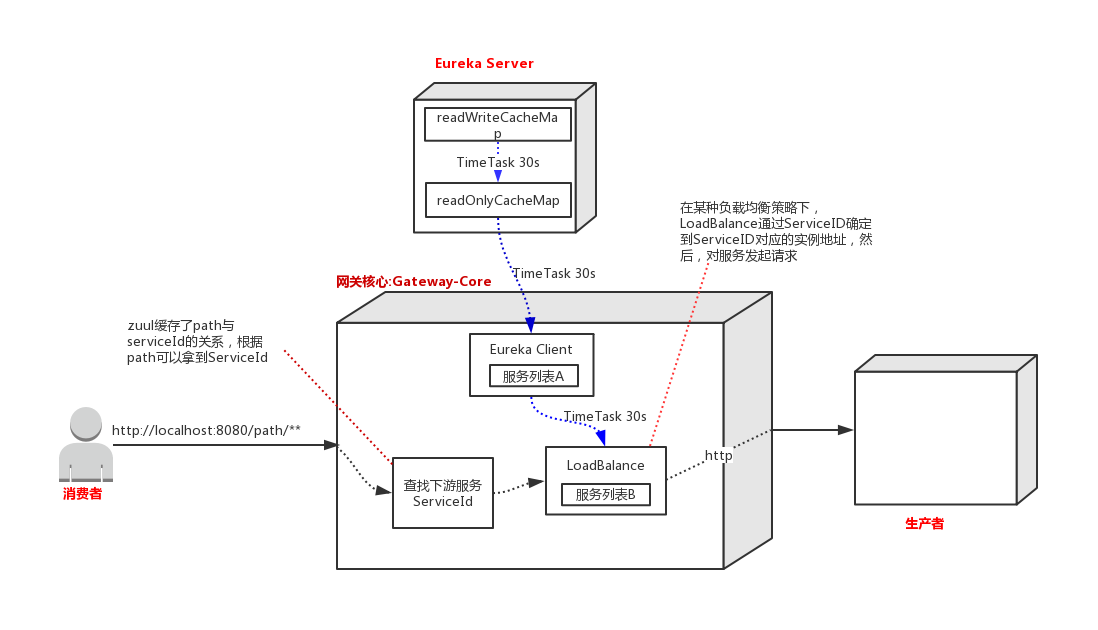
正常情况下,调用方对网关发起请求即刻能得到响应。但是当对生产者做缩容、下线、升级的情况下,由于Eureka这种多级缓存的设计结构和定时更新的机制,LoadBalance 端的服务列表B存在更新不及时的情况,服务消费者最长感知时间将无限趋近240s),如果这时消费者对网关发起请求,LoadBalance 会对一个已经不存在的服务发起请求,请求是会超时的。
Solution
解决方案思路
生产者下线后,最先得到感知的是 Eureka Server 中的 readWriteCacheMap,最后得到感知的是网关核心中的 LoadBalance。但是 loadBalance 对生产者的发现是在 loadBalance 本地维护的列表中。
所以要想达到网关对生产者下线的实时感知,可以这样做:首先生产者或者部署平台主动通知 Eureka Server,然后跳过 Eureka 多级缓存之间的更新时间,直接通知 Zuul 中的 Eureka Client,最后将 Eureka Client 中的服务列表更新到 Ribbon 中。
如果下线通知的逻辑代码放在生产者中,会造成代码污染、语言差异等问题。
Reference
- [Eureka自我保护模式——难点重点] https://www.cnblogs.com/linjiqin/p/10090000.html
- [Spring Cloud Eureka 自我保护机制] https://www.cnblogs.com/xishuai/p/spring-cloud-eureka-safe.html
- [SpringCloud之Eureka] https://juejin.im/post/5ca4ca43e51d4577dd2e82e3
- [Self Preservation Mode] https://github.com/Netflix/eureka/wiki/Server-Self-Preservation-Mode
- [spring cloud eureka 参数配置] https://segmentfault.com/a/1190000008378268
- [详解 Eureka 缓存机制] http://college.creditease.cn/detail/243
- [API网关如何实现对服务下线实时感知] https://juejin.im/post/5cf62c13f265da1bc37efb4c
- [Understanding Eureka Peer to Peer Communication] https://github.com/Netflix/eureka/wiki/Understanding-Eureka-Peer-to-Peer-Communication