Shard
Shard本质上就是一个Lucene索引, 因此会消耗相应的文件句柄, 内存和CPU资源。
一个 Index 其实是有存储上限的(除非你设置足够多的 Shards 和机器),如官方声明单个 Shard 的文档数不能超过 20 亿(受限于 Lucene index,每个 Shard 是一个 Lucene index)。
每个搜索请求会调度到索引的每个分片中. 如果分片分散在不同的节点倒是问题不太. 但当分片开始竞争相同的硬件资源时, 性能便会逐步下降。
shard_num = hash(_routing) % num_primary_shards
其中 hash(_routing) 得出一个数字,然后除以主 Shards 的数量得到一个余数,余数的范围是 0 到 number_of_primary_shards - 1,这个数字就是文档所在的 Shard。Routing 默认是 id 值,当然可以自定义,合理指定 Routing 能够大幅提升查询效率,Routing 支持 GET、Delete、Update、Post、Put 等操作。
考虑到 I、O,针对 Index 每个 Node 的 Shards 数最好不超过 3 个,那面对这样一个庞大的 Index,我们是采用更多的 Shards,还是更多的 Index,我们如何选择?
Index 的 Shards 总量也不宜太多,更多的 Shards 会带来更多的 I、O 开销,其实答案就已经很明确,除非你能接受长时间的查询等待。
Index 拆分的思路很简单,时序索引有一个好处就是只有增加,没有变更,按时间累积,天然对索引的拆分友好支持,可以按照时间和数据量做任意时间段的拆分。
ES 提供的 Rollover Api + Index Template 可以非常便捷和友好的实现 Index 的拆分工作,把单个 index docs 数量控制在百亿内,也就是一个 Index 默认 5 个 Shards 左右即可,保证查询的即时响应。
Shard Count
当我们节点数和Shard数相等时,ElasticSearch 集群的性能可以达到最优。即,对于一个3节点集群,我们为每个集群节点分配1个 Shard,总共3个 Shard。
但是由于 ElasticSearch 的不可变性(Immutable)的限制,系统无法对 Shard 进行重新拆分分配,除非重新索引这个文件集合。所以,当我们需要增加更多节点的时候,又希望 Shard 能利用到增加节点带来的系统性能提升时,我们就不得不进行重新索引,由于重索引开销巨大,这是我们不希望看到的。
如果单个node分配多个Shard,就会引入另外一系列的性能问题,我们知道对于任意一次完整的搜索,ElasticSearch会分别对每个Shard进行查询,最后进行汇总。当节点数和Shard数是一对一的时候,所有的查询可以并行运行。但是,对于具有多个Shard的节点,如果磁盘是15000RPM或SSD,可能会相对较快,但是这也会存在等待响应的问题,所以通常不推荐一个节点超过2个Shard。
3节点6个Shard,即每个节点2个Shard,这可以使我们在未来轻松的横向扩展到6个节点,应对许多极端的场景。
Replica Count
Replica也是Shard,与Shard不同的是,Replica只会参与读操作,同时也能提高集群的可用性。
对于Replica来说,它的主要作用就是提高集群错误恢复的能力,所以Replica的数目与Shard的数目以及Node的数目相关,与Shard不同的是,Replica的数目可以在集群建立之后变更,切代价较小,所以相比Shard的数目而言,没有那么重要。
如果宕机了,Replica是什么情况?
假设条件: 3 Nodes, 3 Shards, 0 Relicas
假设一个Node宕机
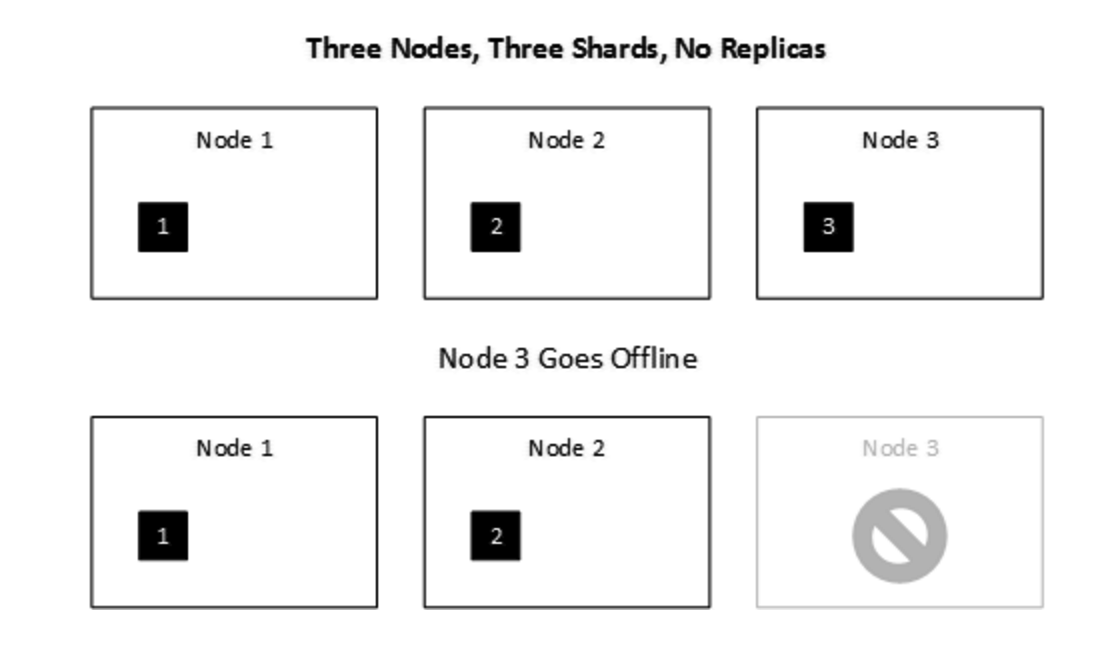
此时,对应的索引不可用。
假设条件: 3 Nodes, 3 Shards, 1 Relicas
假设一个Node宕机
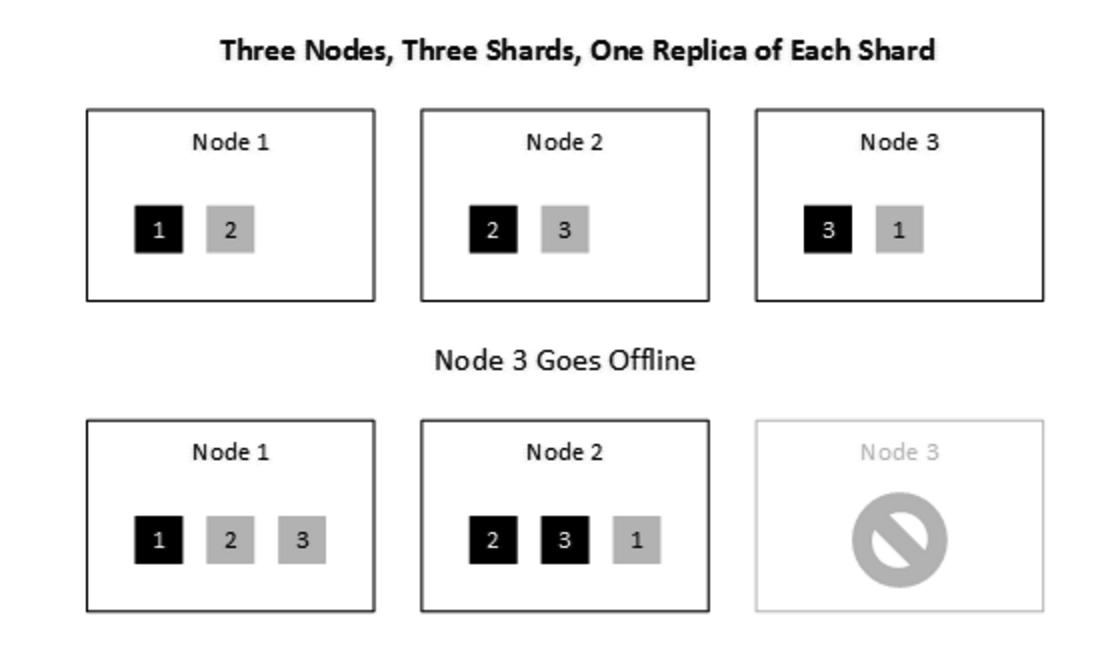
此时,索引可用
假设两个Node宕机
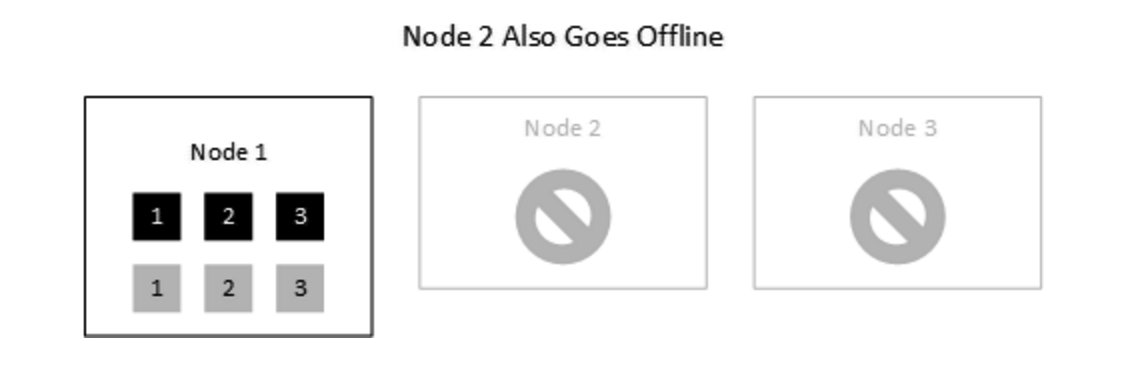
此时,索引仍然可用。
假设条件: 3 Nodes, 3 Shards, 2 Relicas
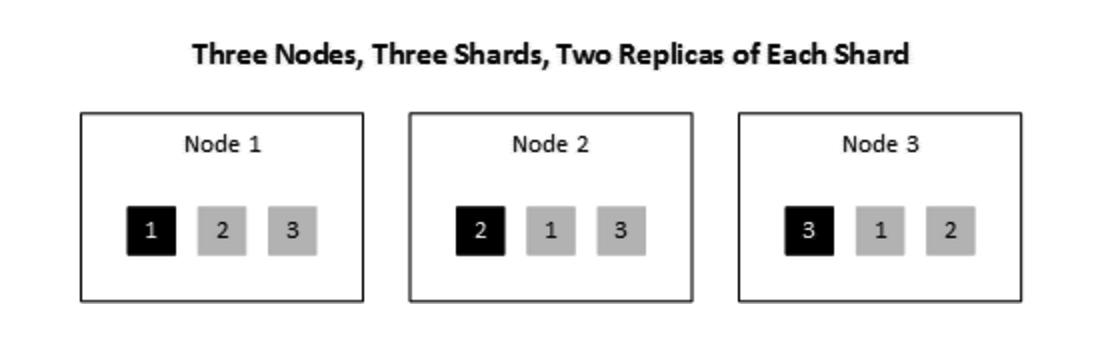
如果存储费用比较便宜,推荐使用