Introduction
测试代码
1 | class StringYGC { |
JVM Options:-XX:+UseConcMarkSweepGC -XX:+PrintGCDetails -Xmx2G -Xms2G -Xmn100M
这里特意将新生代设置比较小,老生代设置比较大,让代码在执行过程中更容易突出问题来,大量做ygc,期间不做CMS GC。
1 | [GC (Allocation Failure) [ParNew: 81920K->8306K(92160K), 0.0087308 secs] 81920K->8306K(2086912K), 0.0087759 secs] [Times: user=0.06 sys=0.01, real=0.01 secs] |
从输出的Log来看,发现YGC不断发生,并且每次YGC时间不断在增长,从9ms慢慢增长到了163ms,甚至还会继续涨下去。原因是什么?
String.intern()
我们先来了解下intern方法的实现,这是String提供的一个方法,JVM提供这个方法的目的是希望对于某个同名字符串使用非常多的场景,在JVM里只保留一份,比如我们不断new String(“Hello”),其实在java heap里会有多个String的对象,并且值都是Hello,如果我们只希望内存里只保留一个Hello,或者希望我接下来用到的地方都返回同一个Hello,那就可以用String.intern这个方法了。
1 | val h1 = "Hello".intern() |
这样 h1 和 h2 都是指向内存里的同一个String对象,那JVM里到底怎么做到的呢?
intern这个方法其实是一个native方法,具体对应到JVM里的逻辑是:
1 | oop StringTable::intern(oop string, TRAPS) |
其实在JVM里存在一个叫做StringTable的数据结构,这个数据结构是一个Hashtable,在我们调用String.intern的时候其实就是先去这个StringTable里查找是否存在一个同名的项,如果存在就直接返回对应的对象,否则就往这个table里插入一项,指向这个String对象,那么再下次通过intern再来访问同名的String对象的时候,就会返回上次插入的这一项指向的String对象。
JVM里提供一个参数专门来控制这个table的size,-XX:StringTableSize,既然有这个参数,那么意味着StringTable是size是固定的。
当发生Hash碰撞的时候,你就要对其对应的桶挨个遍历,超过了100个还是没有找到对应的同名的项,那就会设置一个flag,让下次进入到safepoint的时候做一次rehash动作,尽量减少碰撞的发生,但是当恶化到一定程度的时候,其实也没啥办法啦,因为你的数据量实在太大,桶子数就那么多,那每个桶再怎么均匀也会带着一个很长的链表,所以此时我们通过修改上面的StringTableSize将桶数变大,可能会一定程度上缓解,但是如果是java代码的问题导致泄露,那就只能定位到具体的代码进行改造了。
在JDK6及之前的版本,字符串常量池是放在Perm Gen(也就是方法区)中。
在JDK7版本,字符串常量池被移到了堆中了。至于为什么移到堆内,大概是由于方法区的内存空间太小了。
StringTable为什么会影响YGC
YGC中对StringTable处理的具体代码:
1 | if (!_process_strong_tasks->is_task_claimed(SH_PS_StringTable_oops_do)) { |
因为YGC过程不涉及到对perm做回收,因此collecting_perm_gen是false,而JavaObjectsInPerm默认情况下也是false,表示String.intern返回的字符串是不是在perm里分配,如果是false,表示是在heap里分配的,因此StringTable指向的字符串是在heap里分配的,所以YGC过程需要对StringTable做扫描,以保证处于新生代的String代码不会被回收掉。
设想一下如果StringTable非常庞大,那是不是意味着YGC过程扫描的时间也会变长呢?这也就是解释了为什么StringTable会影响YGC了,
另外一个问题是StringTable什么时候清理?
YGC过程不会对StringTable做清理,这也就是我们demo里的情况会让Stringtable越来越大,但是在FGC或者CMS GC的过程中会对StringTable进行清理。
如何证明?命令 jmap -histo:live
触发FGC
输出SringTable统计信息
JVM Option:-XX:+PrintStringTableStatistics
Testing Code:
1 | class StringYGC { |
GC日志:
1 | [GC (Allocation Failure) [ParNew: 81920K->8477K(92160K), 0.0069494 secs] 81920K->8477K(2086912K), 0.0069858 secs] [Times: user=0.05 sys=0.01, real=0.01 secs] |
SymbolTable statistics:
1 | StringTable statistics: |
- Average bucket size:bucket中LinkedList的平均size。
- Maximum bucket size:表示bucket中LinkedList最大的size。
- Number of entries:Hashtable的entry数量。
- Number of buckets:bucket数量。
Average bucket size越大,说明Hashtable碰撞越严重,由于bucket数量固定为60013,随着StringTable添加的引用越来越多,碰撞越来越严重,YGC时间越来越长。
Comparing Testing
GC日志:
1 | [GC (Allocation Failure) [ParNew: 81920K->8819K(92160K), 0.0083969 secs] 81920K->8819K(2086912K), 0.0084334 secs] [Times: user=0.06 sys=0.00, real=0.01 secs] |
1 | StringTable statistics: |
对比上面的结果,Average bucket size降低很明显。
设置StringTableSize一个合适的值,即bucket数量为期望的数量后,碰撞的概率明显降低,由Average bucket size和Maximum bucket size的值明显小于未配置StringTableSize参数时的值可知,且YGC时间也明显降低。另外, 最好通过BTrace分析是哪里频繁调用String.intern(), 确实String.intern()没有滥用的前提下, 再增大StringTableSize的值。
为什么StringTable不能扩大?
既然StringTable是Hashtable数据结构,那为什么不能自己通过rehash扩大bucket数量来提高性能呢?JVM中StringTable的rehash有点不一样,JVM中StringTable的rehash不会扩大bucket数量,而是在bucket不变的前提下,通过一个新的seed尝试摊平每个bucket中LinkedList的长度。
rehash大概是一个如下图所示的过程,rehash前后bucket数量不变,这是重点:
假设reash前数据分布(23,4,8,2,1,5)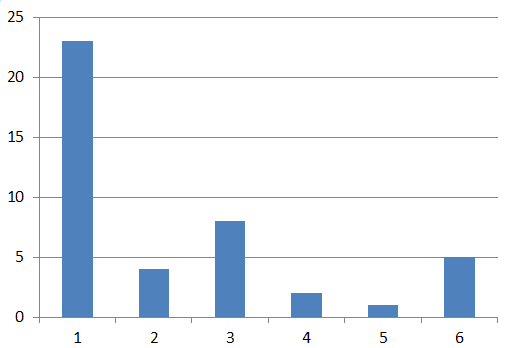
假设reash前数据分布(6,8,8,9,5,7)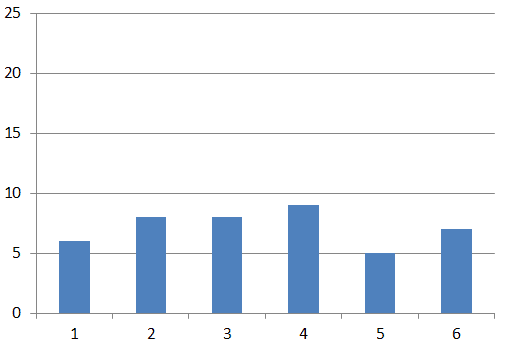
Disable Jackson String.intern
1 | // com.fasterxml.jackson.core.util.InternCache.intern(InternCache.java:45) |
jackson之所以用intern去处理,本来是想节省点cache的内存,没想到业务场景是每次都不一样的字符串,这样直接就导致了String.intern后StringTable的大小暴涨,所以在这种场景中,这样做反而得不偿失,还好jackson代码支持通过接口来把调用intern的部分关掉。
CANONICALIZE_FIELD_NAMES (default: true)
- Means that once name String is decoded from input (byte or char stream), it will be added in a symbol table, to reduce overhead of decoding same name next time it is seen (by any parser constructed by same factory)
INTERN_FIELD_NAMES (default: true)
- If canonicalization is enabled, this feature determines whether String decoded is also interned (using String.intern()) or not – doing that can help further improve deserialization performance since identity comparison may be used.
- If names are unlikely to repeat, or if sheer number of distinct names is huge (in tens of thousands or above), it may make sense to disable this feature.
Disable using String.intern() method:
1 | val factory = JsonFactory().disable(JsonFactory.Feature.INTERN_FIELD_NAMES) |
Reference
http://lovestblog.cn/blog/2016/11/06/string-intern/
https://juejin.im/post/5ab99afff265da23a2291dee
Refresh:https://coolshell.cn/articles/9606.html
https://www.jianshu.com/p/5524fce8b08f
http://hellojava.info/?p=514
Jackson触发的String.intern():https://www.cnblogs.com/halberts/p/7473857.html