Introduction
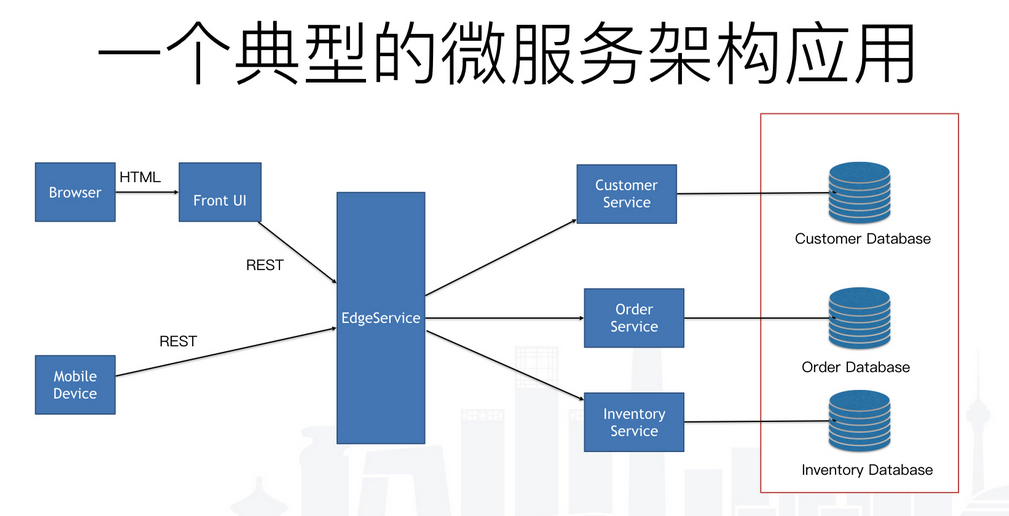
在微服务架构中,有一个database per service的模式,这个模式就是每一个服务一个数据库。 这样可以保证微服务独立开发,独立演进,独立部署,独立团队。
由于对外提供的服务是由一组相互协作的微服务所组成,在分布式环境下由于各个服务访问的数据是相互分离的,服务之间不能靠数据库来保证事务一致性。这就需要在应用层面提供一个协调机制,来保证一组事务执行要么成功,要么失败。
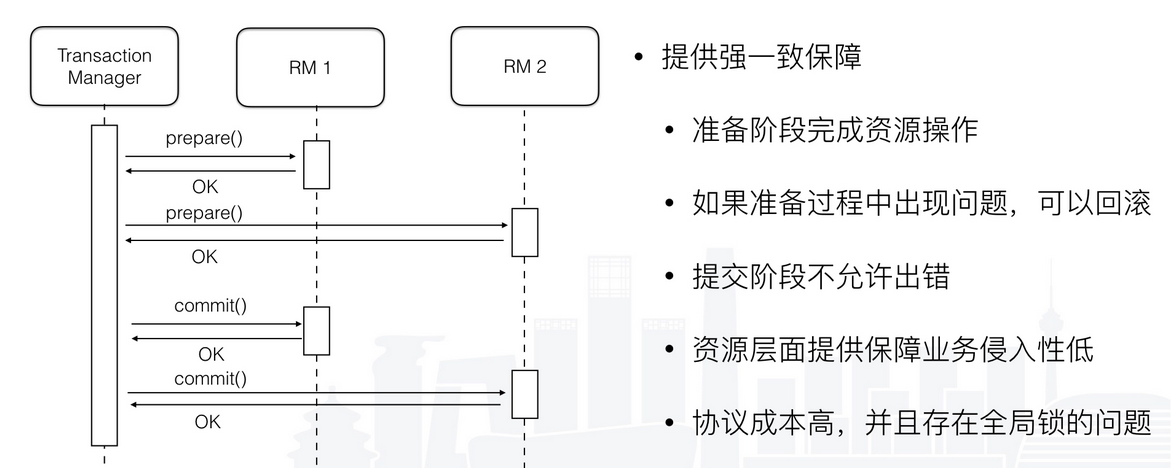
由于隔离性互斥的要求,在事务执行过程中,所有的资源都是被锁定的,这种情况只适合执行时间确定的短事务。但是为了保证分布式事务的一致性,大都是采用串行化的隔离级别来保证事务一致性,这样会降低系统的吞吐。但因为2PC协议的成本比较高,又有全局锁的问题,性能会比较差。现在大家基本上不会采用这种强一致解决方案。
微服务事务一致性建议:
- 微服务内:聚合通过数据库事务保证强一致。
- 微服务间:最终一致。
TCC
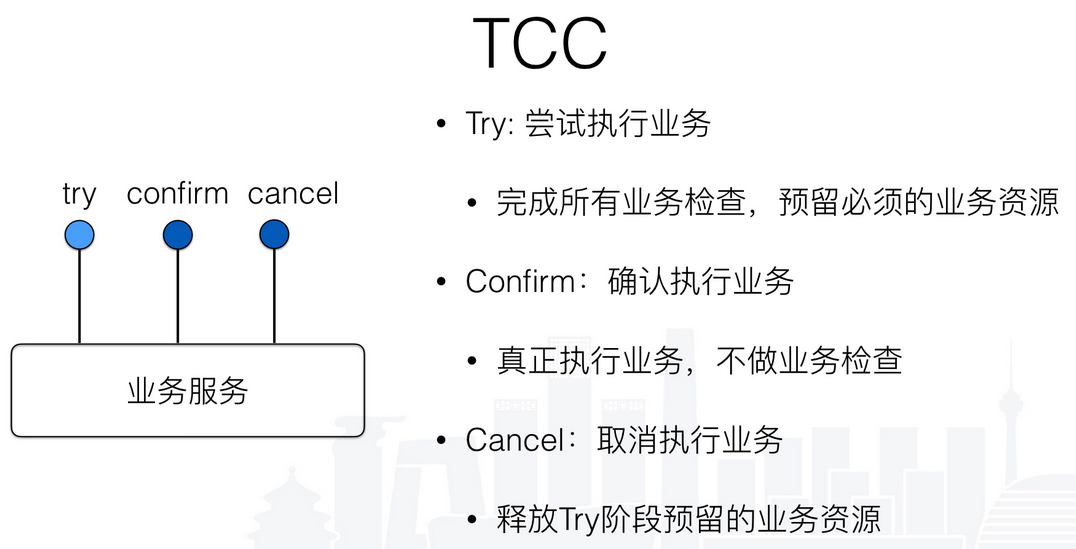
TCC名字的由来是其中包含了try,confirm,cancel三个操作。
与2PC相比,TCC位于业务服务层,没有单独的准备阶段,Try操作可以灵活选择业务资源锁的粒度。TCC是通过最终一致性来解决系统性能问题的这个设计,对我们设计抉择有很大的启发。有些时候系统的技术问题是可以通过业务建模的方式来解决的。
推荐阅读书籍:领域驱动设计和实现领域驱动设计
消息驱动方式
消息一致性方案是通过消息中间件保证上下游应用数据操作的一致性。基本思路是将本地操作和发送消息放在一个事务中,下游应用向消息系统订阅该消息,收到消息后执行相应操作。本质上是依靠消息的重试机制,达到最终一致性。
消息驱动的缺点是:耦合度高,需要在业务系统中引入MQ,导致系统复杂度增加。
Example
A账户往B账户汇款100元,流程如下:
汇款服务和收款服务分别需要实现,Try-Confirm-Cancel接口,并在业务初始化阶段将其注入到TCC事务管理器中。
汇款服务
Try:
- 检查A账户有效性,即查看A账户的状态是否为“转帐中”或者“冻结”;
- 检查A账户余额是否充足;
- 从A账户中扣减100元,并将状态置为“转账中”;
- 预留扣减资源,将从A往B账户转账100元这个事件存入消息或者日志中;
Confirm:不做任何操作
Cancel:
- A账户增加100元;
- 从日志或者消息中,释放扣减资源。
收款服务
Try:
- 检查B账户账户是否有效;
Confirm:
- 读取日志或者消息,B账户增加100元;
- 从日志或者消息中,释放扣减资源;
Cancel:不做任何操作。
小结
由此可以看出,TCC模型对业务的侵入强,改造的难度大。
Sage
Saga其实是30年前的一篇数据库论文里提到的一个概念。在论文中一个Saga事务就是一个长期运行的事务,这个事务是由多个本地事务所组成,每个本地事务有相应的执行模块和补偿模块,当Saga事务中的任意一个本地事务出错了,可以通过调用相关事务对应的补偿方法恢复,达到事务的最终一致性。
在分布式系统中由于网络请求可能的延时,在Caitie的论文中对被Saga调用的服务提出两点要求:
- 超时重试的机制,需要Saga调用的服务支持幂等。在服务请求的过程中,可能会出现超时重试的情况,我们需要通过幂等来避免多次请求所带来的问题。
- 重试取消的机制,补偿可交换原则是指Saga并行处理的过程中,如果发生了超时重试事件之后,并进行了补偿的操作,那么补偿操作是直接生效的。
主要参考了Caitie McCaffrey在分布式Saga论文,以及Chris Richardson的研究
Theory
Saga模型把一个分布式事务拆分为多个本地事务,每个本地事务都有相应的执行模块和补偿模块( TCC中的Confirm和Cancel)。当Saga事务中任意一个本地事务出错时,可以通过调用相关的补偿方法恢复之前的事务,达到事务最终的一致性。
当每个Saga子事务 T1, T2, …, Tn 都有对应的补偿定义 C1, C2, …, Cn-1,那么Saga系统可以保证:
- 子事务序列 T1, T2, …, Tn得以完成 (最佳情况);
- 或者序列 T1, T2, …, Tj, Cj, …, C2, C1, 0 < j < n, 得以完成。
由于Saga模型中没有Prepare阶段,因此事务间不能保证隔离性,当多个Saga事务操作同一资源时,就会产生更新丢失、脏数据读取等问题,这时需要在业务层控制并发,例如:
- 在应用层面加锁;
- 应用层面预先冻结资源。
Saga恢复方式:
- 向后恢复:补偿所有已完成的事务,如果任一子事务失败;
- 向前恢复:重试失败的事务,假设每个子事务最终都会成功。
显然,向前恢复没有必要提供补偿事务,如果你的业务中,子事务(最终)总会成功,或补偿事务难以定义或不可能,向前恢复更符合你的需求。理论上补偿事务永不失败,然而,在分布式世界中,服务器可能会宕机、网络可能会失败,甚至数据中心也可能会停电,这时需要提供故障恢复后回退的机制,比如人工干预。
ACID与Sage

为了满足重试取消的机制,需要我们在设计系统的过程中保留所有的事务数据。但是从上图可知,Saga模型只支持ACD,不提供隔离性的保证。
如果Sage缺少了隔离性会带来什么问题?
- 两个Sage事务同时操作一个资源会出现数据语义不一致的情况。
- 两个Sage事务同时操作一个订单,彼此操作会覆盖对比(更新丢失)。
- 两个Sage事务同时访问扣款账号,无法看到退款(脏读取问题)。
- 在一个Sage事务内,数据被其他事务修改前后的读取值不一致(模糊读取问题)。
如何应对隔离性问题?
隔离的本质是控制并发,防止并发事务操作相同资源而引起结果错乱。
- 在应用层面加入逻辑锁的逻辑。
- Session层面,Session以及锁的机制保证串行化操作资源。
- 业务层面采用预先冻结资金的方式隔离此部分资金。
- 业务操作过程中通过及时读取当前状态的方式获取更新。
实现方式
Orchestration-Base Coordination - 集中式:集中式协调器负责服务调用以及事务协调。
Choreography-Base Coordination - 分布式:通过事件驱动的方式来进行事务协调。
FESCAR - Fast & Easy Commit And Rollback
假设某个业务共有 3 个模块,在传统的单体应用中,每个业务模块可以使用单个的本地数据源,这样本地事务自然就可以保证数据一致性。而在微服务架构中,业务模块会被设计成为3个不同数据源上的3个服务,每个服务对应一个数据库,本地事务当然也可以保证每个服务中的数据一致性,但是扩展到整个应用、整个业务逻辑范围来看,情况如何呢?
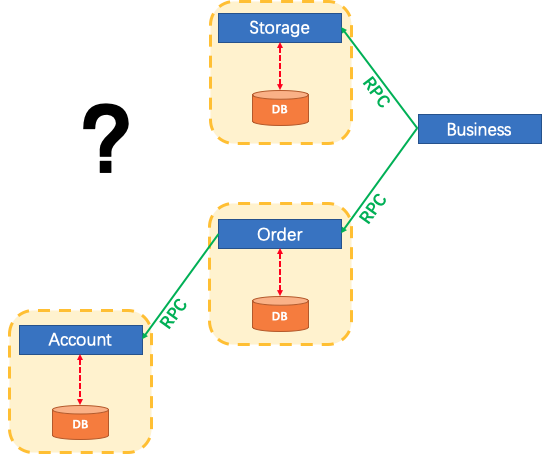
FESCAR解决方案是:
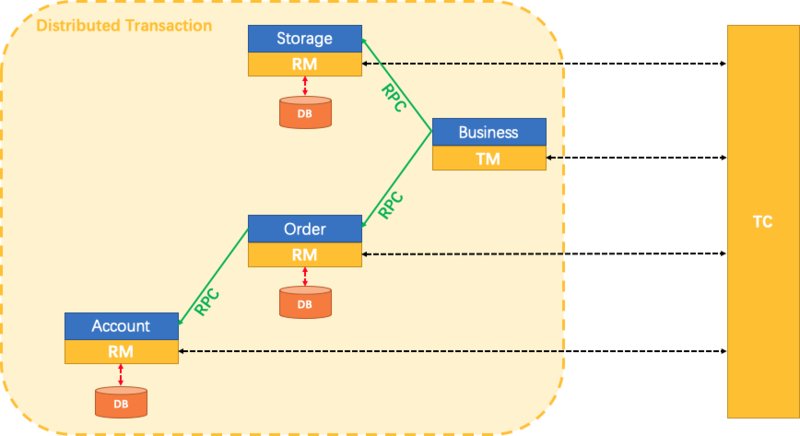
分布式事务是一个全局事务,由一批Branch Transation组成,通常Branch Transation只是本地事务。
三大基本组件
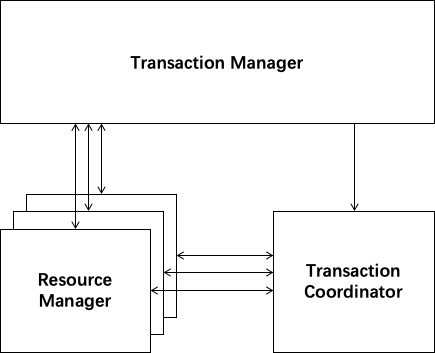
- Transaction Coordinator(TC):维护全局和分支事务的状态,驱动全局事务提交与回滚。
- Transaction Manager™:定义全局事务的范围:开始、提交或回滚全局事务。
- Resource Manager(RM):管理分支事务处理的资源,与TC通信以注册分支事务并报告分支事务的状态,并驱动分支事务提交或回滚。
管理分布式事务的典型生命周期
- TM 要求 TC 开始新的全局事务,TC 生成表示全局事务的 XID。
- XID 通过微服务的调用链传播。
- RM 在 TC 中将本地事务注册为 XID 的相应全局事务的分支。
- TM 要求 TC 提交或回滚 XID 的相应全局事务。
- TC 驱动 XID 的相应全局事务下的所有分支事务,完成分支提交或回滚。