背景
所谓全局唯一的 id 其实往往对应是生成唯一记录标识的业务需求。
这个id常常是数据库的主键,数据库上会建立聚集索引(cluster index),即在物理存储上以这个字段排序。
这个记录标识上的查询,往往又有分页或者排序的业务需求。所以往往要有一个time字段,并且在time字段上建立普通索引(non-cluster index)。
普通索引存储的是实际记录的指针,其访问效率会比聚集索引慢,如果记录标识在生成时能够基本按照时间有序,则可以省去这个time字段的索引查询。
这就引出了记录标识生成的两大核心需求:
- 全局唯一
- 趋势有序
常见生成策略
用数据库的 auto_increment 来生成
优点:
- 此方法使用数据库原有的功能,所以相对简单
- 能够保证唯一性
- 能够保证递增性
- id 之间的步长是固定且可自定义的
缺点:
- 可用性难以保证:数据库常见架构是 一主多从 + 读写分离,生成自增ID是写请求 主库挂了就玩不转了
- 扩展性差,性能有上限:因为写入是单点,数据库主库的写性能决定ID的生成性能上限,并且 难以扩展
单点批量ID生成服务
uuid / guid
优点:
- 本地生成ID,不需要进行远程调用,时延低
- 扩展性好,基本可以认为没有性能上限
缺点:
- 无法保证趋势递增
- uuid过长,往往用字符串表示,作为主键建立索引查询效率低,常见优化方案为“转化为两个uint64整数存储”或者“折半存储”(折半后不能保证唯一性)
取当前毫秒数
优点:
- 本地生成ID,不需要进行远程调用,时延低
- 生成的ID趋势递增
- 生成的ID是整数,建立索引后查询效率高
缺点:
- 如果并发量超过1000,会生成重复的ID
这个缺点要了命了,不能保证ID的唯一性。当然,使用微秒可以降低冲突概率,但每秒最多只能生成1000000个ID,再多的话就一定会冲突了,所以使用微秒并不从根本上解决问题。
使用Redis来生成id
Twitter开源的Snowflake算法
对于分布式的ID生成,以Twitter Snowflake为代表的,Flake系列算法,属于划分命名空间并行生成的一种算法,生成的数据为64bit的long型数据,在数据库中应该用大于等于64bit的数字类型的字段来保存该值,比如在MySQL中应该使用BIGINT。
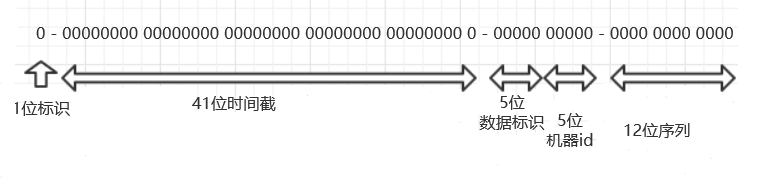
结构说明(64bit):
第一比特位保留
时间戳,41比特,从2016年11月1日零点到现在的毫秒数,可以用到2156年,100多年后才会用完
机器id,10比特,这个机器id每个业务要唯一,机器id获取的策略后面会详述
序列号,12比特,每台机器每毫秒最多产生4096个id,超过这个数的话会等到下一毫秒
特别注意,这个方案所支持的最小划分粒度是「毫秒 * 线程」,单线程(Snowflake 里对应的概念是 Worker)的每毫秒容量是12-bit,也就是接近4096。
该算法存在的问题:
依赖机器时钟,如果机器时钟回拨,会导致重复ID生成
在单机上是递增的,但是由于设计到分布式环境,每台机器上的时钟不可能完全同步,有时候会出现不是全局递增的情况(此缺点可以认为无所谓,一般分布式ID只要求趋势递增,并不会严格要求递增~90%的需求都只要求趋势递增)
Sharding-jdbc
根据机器IP获取工作进程Id,如果线上机器的IP二进制表示的最后10位不重复,建议使用此种方式,列如机器的IP为192.168.1.108,二进制表示:11000000 10101000 00000001 01101100 截取最后10位 01 01101100,转为十进制364,设置workerId为364。
注意,机器XXX.XXX.209.55,XXX.XXX.161.55转化为workid,发现都是一样的。只要workerid相同,同时在这两台机器上出现请求,就会产生重复,或者说只要线上IP末尾相同,就有可能会产生重复。
备用方案:根据机器名最后的数字编号获取工作进程编号。如果线上机器命名有统一规范,建议使用此种方式。例如,机器的 HostName 为: dangdang-db-sharding-dev-01(公司名-部门名-服务名-环境名-编号),会截取 HostName 最后的编号 01 作为工作进程编号( workId )。