HashMap
Class主要成员
transient int size:记录了Map中KV对的个数
loadFactor:装载印子,用来衡量HashMap满的程度。loadFactor的默认值为0.75f。(static final float DEFAULT_LOAD_FACTOR = 0.75f)
int threshold:临界值,当实际KV个数超过threshold时,HashMap会将容量扩容,threshold=容量*加载因子
capacity:容量,如果不指定,默认容量是16。(static final int DEFAULT_INITIAL_CAPACITY = 1 << 4)
- size和capacity的关系
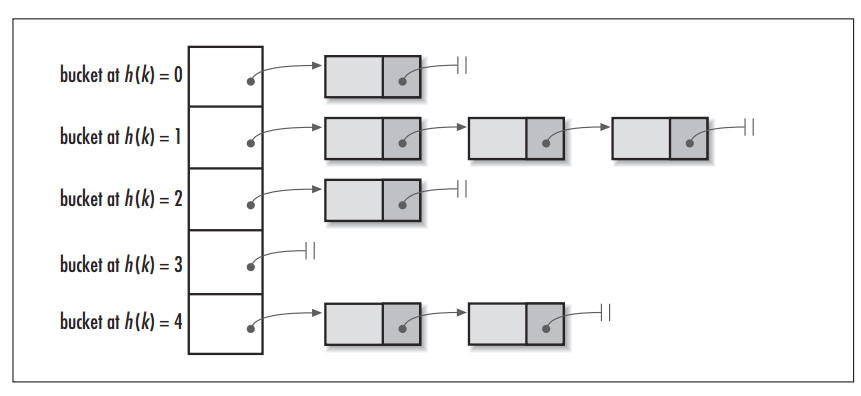
HashMap就像一个“桶”,那么capacity就是这个桶“当前”最多可以装多少元素,而size表示这个桶已经装了多少元素。
- 动态扩容
如果你需要存储大量数据,你应该在创建HashMap时指定一个初始的容量,这个容量应该接近你期望的大小。
默认情况下HashMap的容量是16,但是,如果用户通过构造函数指定了一个数字作为容量,那么Hash会选择大于该数字的第一个2的幂作为容量。(1->1、7->8、9->16)
HashMap的扩容条件就是当HashMap中的元素个数(size)超过临界值(threshold)时就会自动扩容。
在HashMap中,threshold = loadFactor * capacity。
loadFactor是装载因子,表示HashMap满的程度,默认值为0.75f,设置成0.75有一个好处,那就是0.75正好是3/4,而capacity又是2的幂。所以,两个数的乘积都是整数。
对于一个默认的HashMap来说,默认情况下,当其size大于12(16*0.75)时就会触发扩容,每次扩充为原来的2倍。
如果数据量不大,重建内部数组的操作会很快,但是数据量很大时,花费的时间可能会从秒级到分钟级。通过初始化时指定Map期望的大小,你可以避免调整大小操作带来的消耗。
但这里也有一个缺点:如果你将数组设置的非常大,例如2^28,但你只是用了数组中的2^26个桶,那么你将会浪费大量的内存(在这个示例中大约是2^30字节)。
- 常见的Hash函数
直接定址法:直接以关键字k或者k加上某个常数(k+c)作为哈希地址。
数字分析法:提取关键字中取值比较均匀的数字作为哈希地址。
除留余数法:用关键字k除以某个不大于哈希表长度m的数p,将所得余数作为哈希表地址。
分段叠加法:按照哈希表地址位数将关键字分成位数相等的几部分,其中最后一部分可以比较短。然后将这几部分相加,舍弃最高进位后的结果就是该关键字的哈希地址。
平方取中法:如果关键字各个部分分布都不均匀的话,可以先求出它的平方值,然后按照需求取中间的几位作为哈希地址。
伪随机数法:采用一个伪随机数当作哈希函数。
衡量一个哈希函数的好坏的重要指标就是发生碰撞的概率以及发生碰撞的解决方案。任何哈希函数基本都无法彻底避免碰撞,常见的解决碰撞的方法有以下几种:
开放定址法:开放定址法就是一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录存入。
链地址法:将哈希表的每个单元作为链表的头结点,所有哈希地址为i的元素构成一个同义词链表。即发生冲突时就把该关键字链在以该单元为头结点的链表的尾部。
再哈希法:当哈希地址发生冲突用其他的函数计算另一个哈希函数地址,直到冲突不再产生为止。
建立公共溢出区:将哈希表分为基本表和溢出表两部分,发生冲突的元素都放入溢出表中。
- 数据结构
数组的特点是:寻址容易,插入和删除困难;链表的特点是:寻址困难,插入和删除容易。
- 为什么使用位运算(&)来实现取模运算(%)?
位运算(&)效率要比代替取模运算(%)高很多,主要原因是位运算直接对内存数据进行操作,不需要转成十进制。
1 | X % 2^n = X & (2^n – 1) |
性能测试
- Example JDK1.7
创建3个HashMap,分别使用默认的容量(16)、使用元素个数的一半(5千万)作为初始容量、使用元素个数(一亿)作为初始容量进行初始化。然后分别向其中put一亿个KV。
测试结果:1
2
3未初始化容量,耗时 : 14419
初始化容量5000000,耗时 : 11916
初始化容量为10000000,耗时 : 7984
参考链接
http://www.hollischuang.com/archives/2091
HashSet
一般情况下,建议使用默认大小
ConcurrentSkipListMap
ConcurrentSkipListMap 一个并发安全, 基于 skip list 实现有序存储的Map
ConcurrentSkipListMap 的存取时间是log(N),和线程数几乎无关。
在非多线程的情况下,应当尽量使用TreeMap。
参考链接
https://blog.csdn.net/guangcigeyun/article/details/8278349
TreeMap
Error
- java.util.ConcurrentModificationException
分析:当我们迭代一个ArrayList或者HashMap时,如果尝试对集合做一些修改操作(例如删除元素),可能会抛出java.util.ConcurrentModificationException的异常。
解决方案:使用ConcurrentSkipListMap;