微服务特点
微服务的特点决定了功能模块的部署是分布式的,以往在单应用环境下,所有的业务都在同一个服务器上,如果服务器出现错误和异常,我们只要盯住一个点,就可以快速定位和处理问题,但是在微服务的架构下,大部分功能模块都是单独部署运行的,彼此通过总线交互,都是无状态的服务,这种架构下,前后台的业务流会经过很多个微服务的处理和传递,我们难免会遇到这样的问题:
- 分散在各个服务器上的日志怎么处理?
- 如果业务流出现了错误和异常,如何定位是哪个点出的问题?
- 如何快速定位问题?
- 如何跟踪业务流的处理顺序和结果?
解决方案
Google Dapper
Google公司广泛使用了分布式集群,为了应对自身大规模的复杂集群环境,Google公司研发了Dapper分布式跟踪系统,并发表了论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》,给行业内分布式跟踪的实现提供了非常有价值的参考,该论文也成为了当前分布式跟踪系统的理论基础。
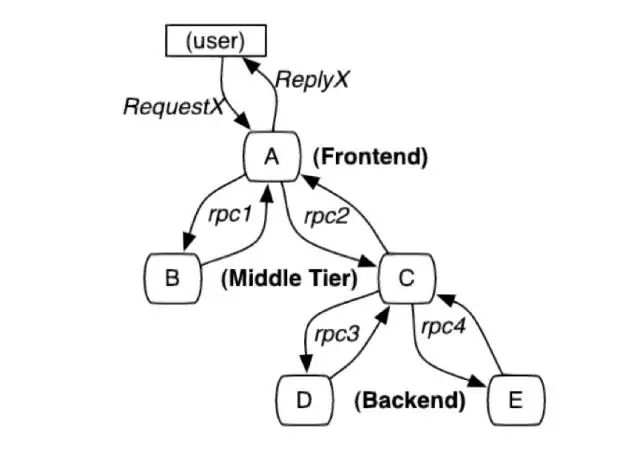
这个路径由用户的X请求发起,穿过一个简单的服务系统。用字母标识的节点代表分布式系统中的不同处理过程。
分布式服务的跟踪系统需要记录在一次特定的请求中系统中完成的所有工作的信息。
举个例子,上图展现的是一个与5台服务器相关的一个服务,包括:前端(A),两个中间层(B和C),以及两个后端(D和E)。当一个用户(这个用例的发起人)发起一个请求时,首先到达前端,然后发送两个RPC调用到服务器B和C。B会马上做出反应,但是C需要和后端的D和E交互之后再返还给A,由A来响应最初的请求。对于这样一个请求,简单实用的分布式跟踪的实现,就是为服务器上每一次发送和接收动作来收集跟踪标识符(message identifiers)和时间戳(timestamped events)。
重要概念
- 基于标注(annotation-based),又叫植入点或埋点
在应用程序或中间件中明确定义一个全局的标注(annotation),它可以是一个特殊的ID,通过这个ID连接每一条记录和发起者的请求,当然,这需要代码植入,在生产环境中,因为所有的应用程序都使用相同的线程模型,控制流和RPC系统,可以把代码植入限制在一个很小的通用组件库中,从而达到监测系统应用对开发人员的透明。Dapper能够以对应用开发者近乎零侵入的成本对分布式控制路径进行跟踪,几乎完全依赖于少量通用组件库的改造。
- 跟踪树和span
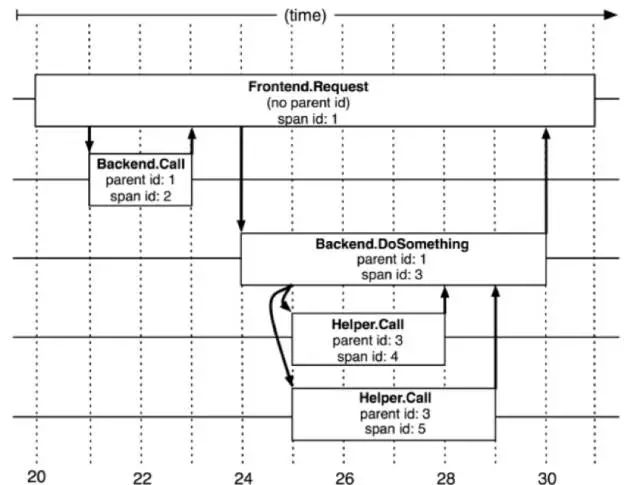
5个span在Dapper跟踪树中的关联关系
在Dapper跟踪树结构中,树节点是整个架构的基本单元,而每一个节点又是对span的引用。节点之间的连线表示的span和它的父span的直接关系。通过简单的parentId和spanId就可以有序地把所有的关系串联起来,达到记录业务流的作用。
Twitter’s Zipkin
Twitter公司的Zipkin是Google Dapper系统的开源实现,Zipkin严格按照Dapper论文实现,采用Scala编写,并且紧密集成到Twitter公司自己的分布式服务Finagle中,使得跟踪做到对应用透明。
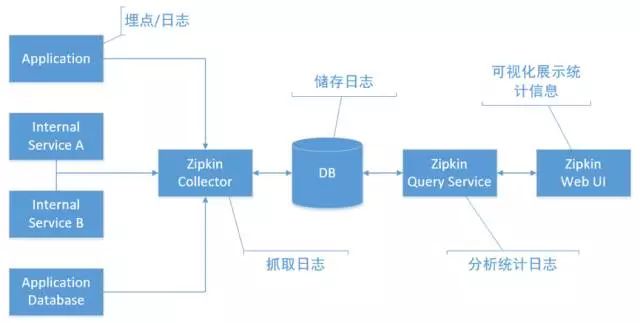
淘宝鹰眼系统(EagleEye)
淘宝鹰眼是基于网络调用日志的分布式跟踪系统,它可以分析网络请求在各个分布式系统之间的调用情况,从而得到处理请求的调用链上的入口URL、应用服务的调用关系,从而找到请求处理瓶颈,定位错误异常的根源位置。同时,业务方也可以在调用链上添加自己的业务埋点日志,使各个系统的网络调用与实际业务内容得到关联。
Spring Cloud Sleuth + Zipkin
分布式RequestId
参考链接