如何将业务逻辑与缓存之间进行解耦?
大部分情况,大家都是把缓存操作和业务逻辑之间的代码交织在一起的,如下图所示:
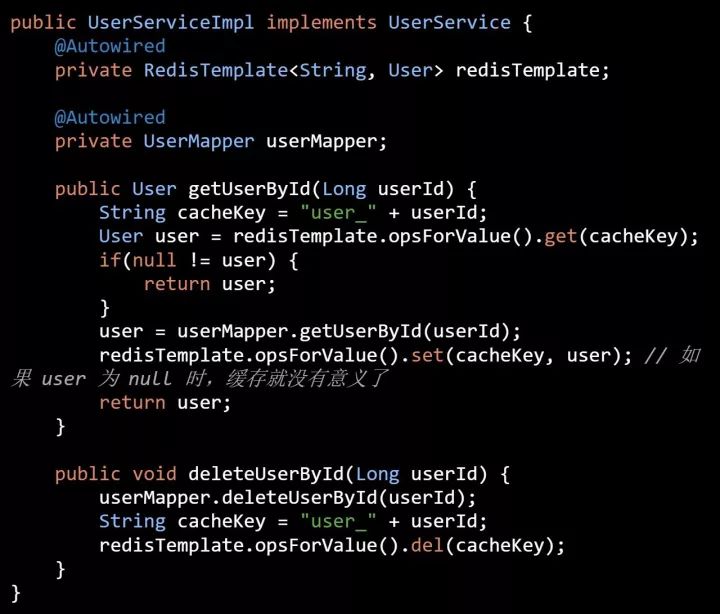
从上面的代码可以看出以下几个问题:
- 缓存操作非常繁琐,产生非常多的重复代码;
- 缓存操作与业务逻辑耦合度非常高,不利于后期的维护;
- 当业务数据为 null 时,无法确定是否已经缓存,会造成缓存无法命中;
- 开发阶段,为了排查问题,经常需要来回开关缓存功能,使用上面的代码是无法做到很方便地开关缓存功能;
- 当业务越来越复杂,使用缓存的地方越来越多时,很难定位哪些数据要进行主动删除;
- 如果不想用 Redis,换用别的缓存技术的话,那是多么痛苦的一件事。
参考一个缓存管理框架 AutoLoadCache处理方式,借鉴 Spring cache 的思想使用 AOP + Annotation 等技术实现缓存与业务逻辑的解耦。
AutoloadCache 在 AOP 拦截到请求后,大概的流程如下:
- 获取到拦截方法的 @Cache 注解,并生成缓存 key;
- 通过缓存 key,去缓存中获取数据;
如果缓存命中,执行如下流程:
如果需要自动加载,则把相关信息保存到自动加载队列中;
否则判断缓存是否即将过期,如果即将过期,则会发起异步刷新;
最后把数据返回给用户。如果缓存没有命中,执行如下流程:
选举出一个 leader回到数据源中去加载数据,加载到数据后通知其它请求从内存中获取数据(拿来主义机制);
leader 负责把数据写入缓存;如果需要自动加载,则把相关信息保存到自动加载队列中;
最后把数据返回给用户。
如何解决缓存 key 冲突问题?
在实际情况中,可能有多个模块共用一个 Redis 服务器或是一个 Redis 集群的情况,那么有可能造成缓存 key 冲突了。
为了解决这个问题 AutoLoadCache,增加了 namespace。如果设置了 namespace 就会在每个缓存 key 最前面增加 namespace

如何减少回源并发数?
当缓存未命中时,都需要回到数据源去取数据,如果这时有多个并发来请求相同一个数据(即相同缓存 key 请求),都回到数据源加载数据,并写缓存,造成资源极大的浪费,也可能造成数据源负载过高而无法服务。
AutoLoadCache 使用 拿来主义机制 和 自动加载机制 来解决这个问题:
拿来主义机制
拿来主交机制,指的是当有多个用户请求同一个数据时,会选举出一个 leader 去数据源加载数据,其它用户则等待其拿到的数据。并由 leader 将数据写入缓存。
自动加载机制
自动加载机制,将用户请求及缓存时间等信息放到一个队列中,后台使用线程池定期扫这个队列,发现缓存即将过期,则去数据源加载最新的数据放到缓存中,达到将数据长驻内存的效果。从而将这些数据的请求,全部引向了缓存,而不会回到数据源去获取数据。这非常适合用于缓存使用非常频繁的数据,以及非常耗时的数据。
为了防止自动加载队列过大,设置了容量限制;同时会将超过一定时间没有用户请求的数据从自动加载队列中移除,把服务器资源释放出来,给真正需要的请求。
往缓存里写数据的性能相比读的性能差非常多,通过上面两种机制,可以减少写缓存的并发,提升缓存服务能力。
异步刷新
AutoLoadCache 从缓存中获取到数据后,借助上面提到的 CacheWrapper,能很方便地判断缓存是否即将过期, 如果即将过期,则会把发起异步刷新请求。
使用异步刷新的目的是提前将数据缓存起来,避免缓存失效后,大量请求穿透到数据源。
多种缓存操作
大部分情况下,我们都是对缓存进行读与写操作,可有时,我们只需要从缓存中读取数据,或者只写数据,那么可以通过 @Cache 的 opType 指定缓存操作类型。现支持以下几种操作类型:
- READ_WRITE:读写缓存操,如果缓存中有数据,则使用缓存中的数据,如果缓存中没有数据,则加载数据,并写入缓存。默认是 READ_WRITE;
- WRITE:从数据源中加载最新的数据,并写入缓存。对数据源和缓存数据进行同步;
- READ_ONLY: 只从缓存中读取,并不会去数据源加载数据。用于异地读写缓存的场景;
- LOAD:只从数据源加载数据,不读取缓存中的数据,也不写入缓存。
批量删除缓存
很多时候,数据查询条件是比较复杂的,我们无法获取或还原要删除的缓存 key。
AutoLoadCache 为了解决这个问题,使用 Redis 的 hash 表来管理这部分的缓存。把需要批量删除的缓存放在同一个 hash 表中,如果需要需要批量删除这些缓存时,直接把这个 hash 表删除即可。这时只要设计合理粒度的缓存 key 即可。
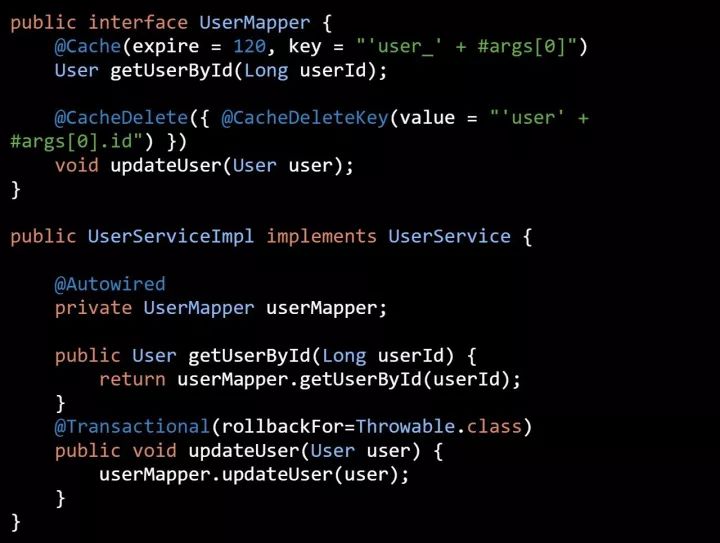
双写不一致问题
使用 updateUser 方法更新用户信息时, 同时会主动删除缓存中的数据。 如果在事务还没提交之前又有一个请求去加载用户数据,这时就会把数据库中旧数据缓存起来,在下次主动删除缓存或缓存过期之前的这一段时间内,缓存中的数据与数据库中的数据是不一致的。
AutoloadCache 框架为了解决这个问题,引入了一个新的注解:@CacheDeleteTransactional
使用 @CacheDeleteTransactional 注解后,AutoloadCache 会先使用 ThreadLocal 缓存要删除缓存 key,等事务提交后再去执行缓存删除操作。其实不能说是“解决不一致问题”,而是缓解而已。
缓存数据双写不一致的问题是很难解决的,即使我们只用数据库(单写的情况)也会存在数据不一致的情况(当从数据库中取数据时,同时又被更新了),我们只能是减少不一致情况的发生。对于一些比较重要的数据,我们不能直接使用缓存中的数据进行计算并回写的数据库中,比如扣库存,需要对数据增加版本信息,并通过乐观锁等技术来避免数据不一致问题。