Reference
- [Log4j2最佳实践] https://www.jianshu.com/p/62c0ef1cc699
1 | docker run -d -p 8081:8081 --name nexus -e INSTALL4J_ADD_VM_PARAMS="-Xms4g -Xmx4g -XX:MaxDirectMemorySize=3g -Djava.util.prefs.userRoot=/nexus-data/user/root" -v $PWD/volume:/nexus-data sonatype/nexus3:3.19.1 |
1 | apiVersion: apps/v1beta1 |
1 | mkdir: cannot create directory '../sonatype-work/nexus3/log': Permission denied |
Solution:修改 /nexus-data 目录的权限为777或者757
1 | nx-repository-view-*-*-* |
1 | nx-repository-view-*-*-add |
1 | <settings> |
1 | <distributionManagement> |
1 | nx-repository-view-*-*-add |
1 | <repositories> |
1 | mvn deploy |
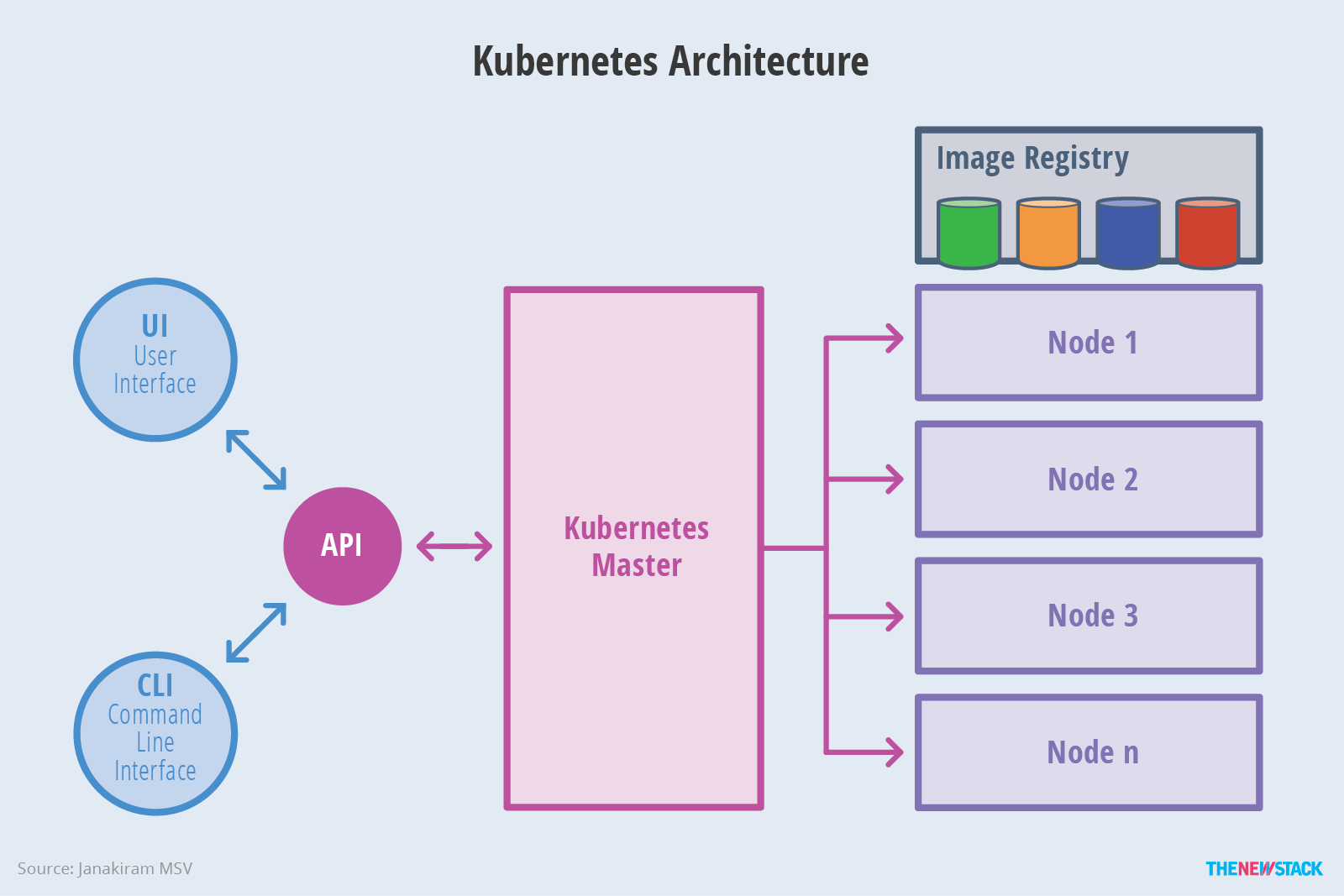
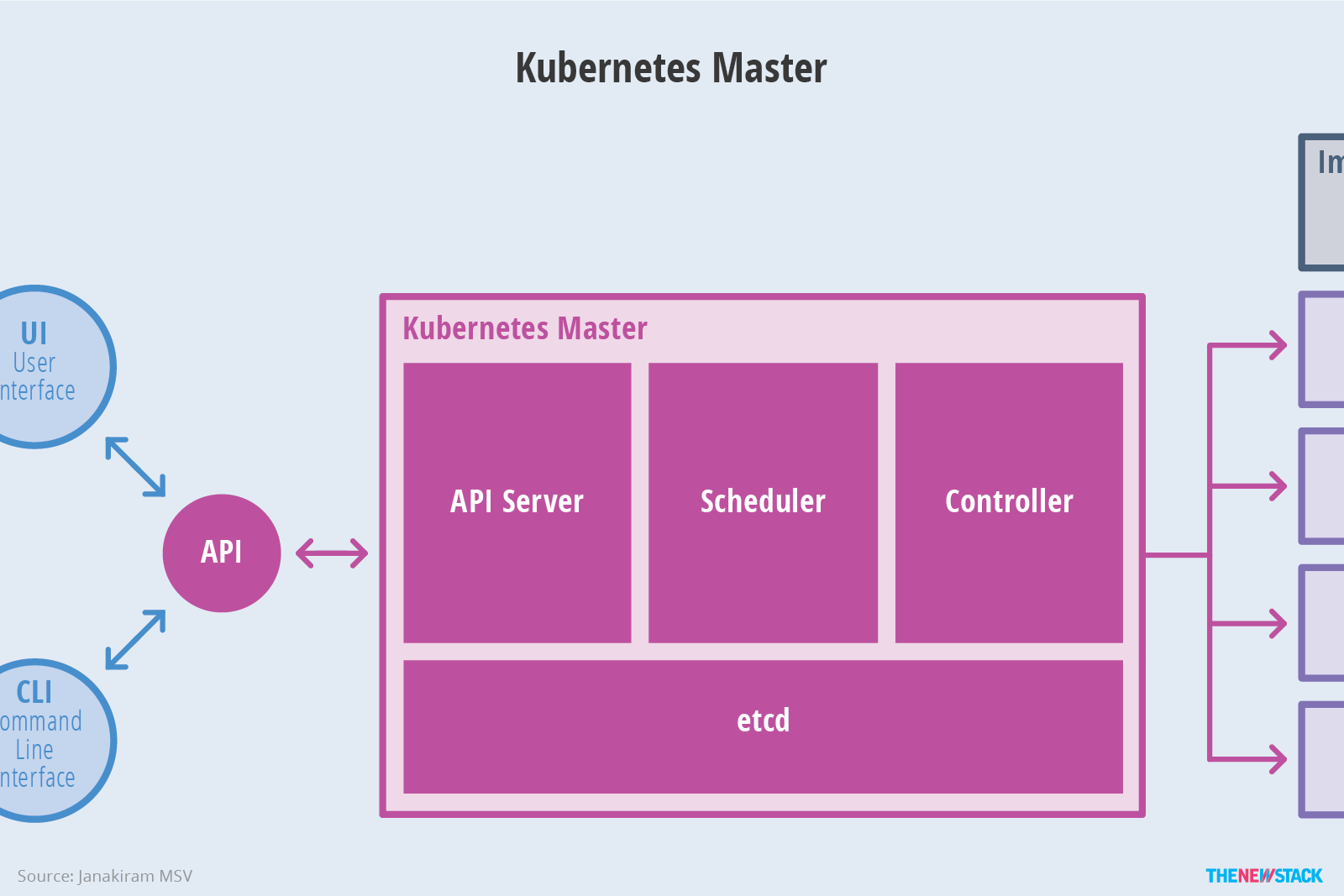
The master is responsible for exposing the application program interface (API), scheduling the deployments and managing the overall cluster.
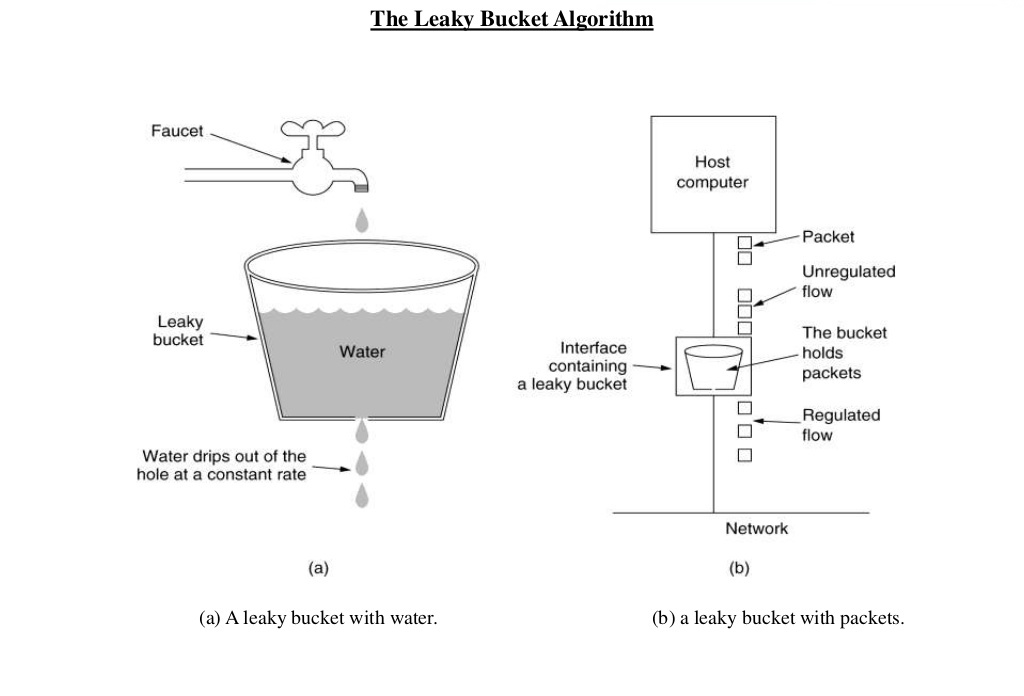
The image shows the usage of leaky bucket algorithm in traffic shaping. If we map(与..有关)) it our limiting requests to server use case, water drops from the faucets(水龙头) are the requests, the bucket is the request queue and the water drops leaked from the bucket are the responses. Just as the water dropping to a full bucket will overflow, the requests arrive after the queue becomes full will be rejected.
Suppose there are a few tokens in a bucket. When a request comes, a token has to be taken from the bucket for it to be processed. If there is no token available in the bucket, the request will be rejected and the requester has to retry later. The token bucket is also refilled per time unit.
Sliding window log algorithm keeps a log of request timestamps for each user. When a request comes, we first pop all outdated timestamps before appending the new request time to the log. Then we decide whether this request should be processed depending on whether the log size has exceeded the limit. For example, suppose the rate limit is 2 requests per minute:

对象池模式一般用来管理一组可重用对象,以供调用组件使用,它可以为组件提供多个完全相同的对象。
Advantage:
Disadvantage:
Object Pool 适用在什么地方?
正常情况下,我们去查询数据都是存在。那么请求去查询一条压根儿数据库中根本就不存在的数据,也就是缓存和数据库都查询不到这条数据,但是请求每次都会打到数据库上面去。这种查询不存在数据的现象我们称为缓存穿透。
如果有黑客会对你的系统进行攻击,拿一个不存在的id去查询数据,会产生大量的请求到数据库去查询。可能会导致你的数据库由于压力过大而宕掉。
1. 缓存空值
之所以会发生穿透,就是因为缓存中没有存储这些空数据的 key。从而导致每次查询都到数据库去了。那么我们就可以为这些 key 对应的值设置为 null 丢到缓存里面去。后面再出现查询这个 key 的请求的时候,直接返回 null,但是别忘了设置过期时间。
2. BloomFilter
BloomFilter 用来判断某个元素(key)是否存在于某个集合中。
这种方式在大数据场景应用比较多,比如 Hbase 中使用它去判断数据是否在磁盘上。还有在爬虫场景判断url 是否已经被爬取过。
这种方案可以加在第一种方案中,在缓存之前在加一层 BloomFilter ,在查询的时候先去 BloomFilter 去查询 key 是否存在,如果不存在就直接返回,存在再走查缓存 -> 查 DB。
小结
针对于一些恶意攻击,攻击带过来的大量 key 是不存在的,那么我们采用第一种方案就会缓存大量不存在key的数据。此时我们采用第一种方案就不合适了,我们完全可以先对使用第二种方案进行过滤掉这些 key。针对这种 key 异常多、请求重复率比较低的数据,我们就没有必要进行缓存,使用第二种方案直接过滤掉。而对于空数据的key有限的,重复率比较高的,我们则可以采用第一种方式进行缓存。
缓存雪崩的情况是说,当某一时刻发生大规模的缓存失效的情况,比如你的缓存服务宕机了,会有大量的请求进来直接打到 DB 上面。结果就是 DB 扛不住而挂掉。
在平常高并发的系统中,大量的请求同时查询一个 key 时,此时这个 key 正好失效了,就会导致大量的请求都打到数据库上面去。这种现象我们称为缓存击穿。
会造成某一时刻数据库请求量过大,压力剧增。
上面的现象是多个线程同时去查询数据库的这条数据,那么我们可以在第一个查询数据的请求上使用一个互斥锁来锁住它。
其他的线程走到这一步拿不到锁就等着,等第一个线程查询到了数据,然后做缓存。后面的线程进来发现已经有缓存了,就直接走缓存。
1 | public String get(key) { |